Prüfer 序列
Note
本文翻译自 e-maxx Prüfer Code.另外解释一下,原文的结点是从 
这篇文章介绍 Prüfer 序列 (Prüfer code),这是一种将带标号的树用一个唯一的整数序列表示的方法.
使用 Prüfer 序列可以证明 凯莱公式(Cayley's formula).并且我们也会讲解如何计算在一个图中加边使图连通的方案数.
注意:我们不考虑含有
Prüfer 序列
引入
Prüfer 序列可以将一个带标号
Heinz Prüfer 于 1918 年发明这个序列来证明 凯莱公式.
对树建立 Prüfer 序列
Prüfer 是这样建立的:每次选择一个编号最小的叶结点并删掉它,然后在序列中记录下它连接到的那个结点.重复
显然使用堆可以做到
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
例如,这是一棵 7 个结点的树的 Prüfer 序列构建过程:
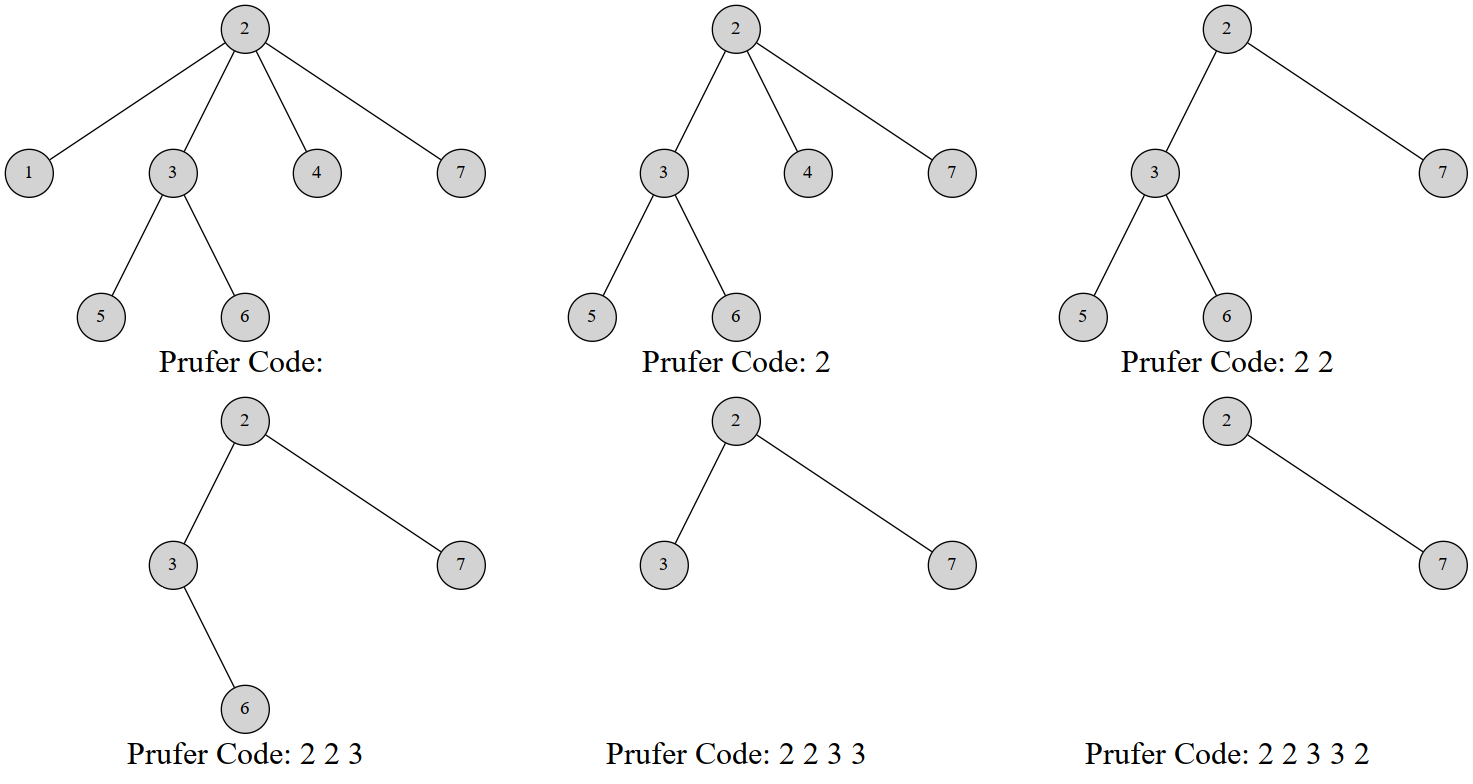
最终的序列就是
当然,也有一个线性的构造算法.
Prüfer 序列的线性构造算法
线性构造的本质就是维护一个指针指向我们将要删除的结点.首先发现,叶结点数是非严格单调递减的,删去一个叶结点,叶结点总数要么不变要么减 1.
于是我们考虑这样一个过程:维护一个指针
- 删除
- 如果产生新的叶结点,假设编号为
- 让指针
正确性
循环上述操作
- 如果
- 如果
算法复杂度分析,发现每条边最多被访问一次(在删度数的时候),而指针最多遍历每个结点一次,因此复杂度是
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
Prüfer 序列的性质
- 在构造完 Prüfer 序列后原树中会剩下两个结点,其中一个一定是编号最大的点
- 每个结点在序列中出现的次数是其度数减
用 Prüfer 序列重建树
重建树的方法是类似的.根据 Prüfer 序列的性质,我们可以得到原树上每个点的度数.然后也可以得到编号最小的叶结点,而这个结点一定与 Prüfer 序列的第一个数所对应的点连接.然后我们同时将这两个结点的度数减一.
讲到这里也许你已经知道该怎么做了.每次我们选择一个度数为
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
线性时间重建树
同线性构造 Prüfer 序列的方法.在删度数的时候会产生新的叶结点,于是判断这个叶结点与指针
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
通过这些过程其实可以理解,Prüfer 序列与带标号无根树建立了双射关系.
Cayley 公式 (Cayley's formula)
完全图
怎么证明?方法很多,但是用 Prüfer 序列证是很简单的.任意一个长度为
图连通方案数
Prüfer 序列可能比你想得还强大.它能创造比 凯莱公式 更通用的公式.比如以下问题:
一个
个点 条边的带标号无向图有 个连通块.我们希望添加 条边使得整个图连通.求方案数.
证明
设
对于第
现在我们要枚举
好的这是一个非常不喜闻乐见的式子.但是别慌!我们有多元二项式定理:
那么我们对原式做一下换元,设
化简得到
即
为答案.
习题
- Luogu P6086【模板】Prüfer 序列(模板题)
- Luogu P11039【MX-X3-T6】「RiOI-4」TECHNOPOLIS 2085
- UVa #10843 - Anne's game
- Timus #1069 - Prufer Code
- Codeforces - Clues
- Topcoder - TheCitiesAndRoadsDivTwo
本页面最近更新:2026/5/13 11:36:39,更新历史
发现错误?想一起完善? 在 GitHub 上编辑此页!
本页面贡献者:Tiphereth-A, sshwy, StudyingFather, countercurrent-time, Enter-tainer, H-J-Granger, NachtgeistW, Early0v0, SamZhangQingChuan, alphagocc, AngelKitty, CCXXXI, cjsoft, diauweb, ezoixx130, GekkaSaori, HeRaNO, iamtwz, Ir1d, Konano, LovelyBuggies, Makkiy, mgt, minghu6, P-Y-Y, PotassiumWings, Suyun514, weiyong1024, aofall, c-forrest, CoelacanthusHex, GavinZhengOI, Gesrua, gi-b716, ImpleLee, jifbt, ksyx, kxccc, lailai0916, Laksurk, Leasier, lychees, Marcythm, Menci, ouuan, partychicken, Peanut-Tang, Persdre, r-value, shawlleyw, shuzhouliu, SukkaW, Xeonacid, zhb2000, zhuyifan314, ZnPdCo
本页面的全部内容在 CC BY-SA 4.0 和 SATA 协议之条款下提供,附加条款亦可能应用