最小生成树 定义 在阅读下列内容之前,请务必阅读 图论相关概念 与 树基础 部分,并了解以下定义:
生成子图 生成树 我们定义无向连通图的 最小生成树 (Minimum Spanning Tree,MST)为边权和最小的生成树.
注意:只有连通图才有生成树,而对于非连通图,只存在生成森林.
Kruskal 算法 Kruskal 算法是一种常见并且好写的最小生成树算法,由 Kruskal 发明.该算法的基本思想是从小到大加入边,是个贪心算法.
前置知识 并查集 、贪心 、图的存储 .
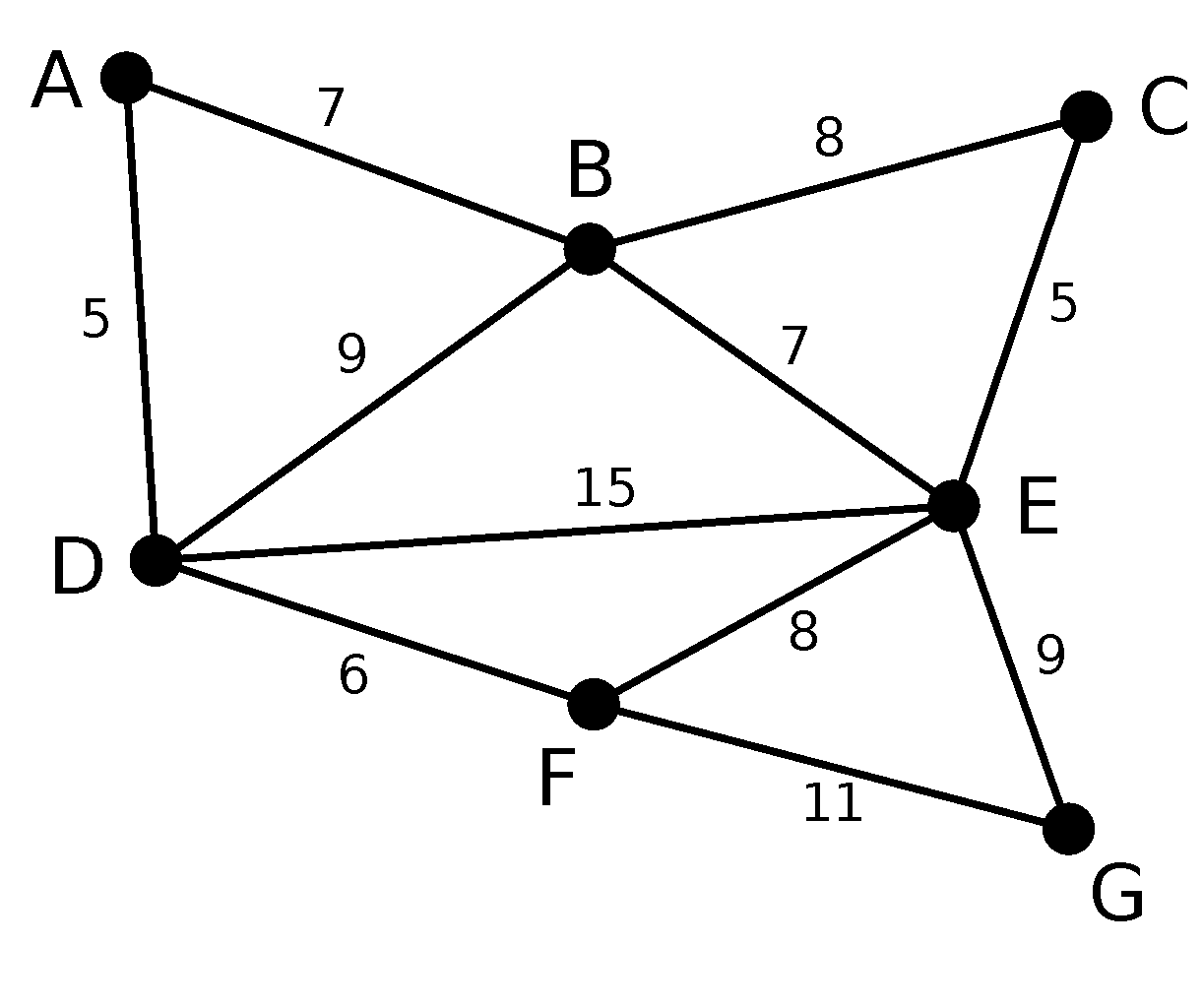
实现 图示:
伪代码:
1 𝐈 𝐧 𝐩 𝐮 𝐭 . T h e e d g e s o f t h e g r a p h 𝑒 , w h e r e e a c h e l e m e n t i n 𝑒 i s ( 𝑢 , 𝑣 , 𝑤 ) d e n o t i n g t h a t t h e r e i s a n e d g e b e t w e e n 𝑢 a n d 𝑣 w e i g h t e d 𝑤 . 2 𝐎 𝐮 𝐭 𝐩 𝐮 𝐭 . T h e e d g e s o f t h e M S T o f t h e i n p u t g r a p h . 3 𝐌 𝐞 𝐭 𝐡 𝐨 𝐝 . 4 𝑟 𝑒 𝑠 𝑢 𝑙 𝑡 ← ∅ 5 s o r t 𝑒 i n t o n o n d e c r e a s i n g o r d e r b y w e i g h t 𝑤 6 𝐟 𝐨 𝐫 e a c h ( 𝑢 , 𝑣 , 𝑤 ) i n t h e s o r t e d 𝑒 7 𝐢 𝐟 𝑢 a n d 𝑣 a r e n o t c o n n e c t e d i n t h e u n i o n - f i n d s e t 8 c o n n e c t 𝑢 a n d 𝑣 i n t h e u n i o n - f i n d s e t 9 𝑟 𝑒 𝑠 𝑢 𝑙 𝑡 ← 𝑟 𝑒 𝑠 𝑢 𝑙 𝑡 ⋃ { ( 𝑢 , 𝑣 , 𝑤 ) } 1 0 𝐫 𝐞 𝐭 𝐮 𝐫 𝐧 𝑟 𝑒 𝑠 𝑢 𝑙 𝑡 1 Input. The edges of the graph e , where each element in e is ( u , v , w ) denoting that there is an edge between u and v weighted w . 2 Output. The edges of the MST of the input graph . 3 Method. 4 r e s u l t ← ∅ 5 sort e into nondecreasing order by weight w 6 for each ( u , v , w ) in the sorted e 7 if u and v are not connected in the union-find set 8 connect u and v in the union-find set 9 r e s u l t ← r e s u l t ⋃ { ( u , v , w ) } 10 return r e s u l t 算法虽简单,但需要相应的数据结构来支持……具体来说,维护一个森林,查询两个结点是否在同一棵树中,连接两棵树.
抽象一点地说,维护一堆 集合 ,查询两个元素是否属于同一集合,合并两个集合.
其中,查询两点是否连通和连接两点可以使用并查集维护.
如果使用 𝑂 ( 𝑚 l o g 𝑚 ) O ( m log m ) 𝑂 ( 𝑚 𝛼 ( 𝑚 , 𝑛 ) ) O ( m α ( m , n ) ) 𝑂 ( 𝑚 l o g 𝑛 ) O ( m log n ) 𝑂 ( 𝑚 l o g 𝑚 ) O ( m log m )
证明 思路很简单,为了造出一棵最小生成树,我们从最小边权的边开始,按边权从小到大依次加入,如果某次加边产生了环,就扔掉这条边,直到加入了 𝑛 − 1 n − 1
证明:使用归纳法,证明任何时候 K 算法选择的边集都被某棵 MST 所包含.
基础:对于算法刚开始时,显然成立(最小生成树存在).
归纳:假设某时刻成立,当前边集为 𝐹 F 𝑇 T 𝑒 e
如果 𝑒 e 𝑇 T
否则,𝑇 + 𝑒 T + e 𝐹 F 𝑓 f
首先,𝑓 f 𝑒 e 𝑓 f 𝑒 e
然后,𝑓 f 𝑒 e 𝑇 + 𝑒 − 𝑓 T + e − f 𝑇 T
所以,𝑇 + 𝑒 − 𝑓 T + e − f 𝐹 F
例题 洛谷 P1195 口袋的天空 有 𝑛 n 𝑘 k 𝑋 𝑖 X i 𝑌 𝑖 Y i 𝐿 𝑖 L i
例题代码 C++ Python Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69 #include <algorithm>
#include <iostream>
using namespace std ;
int fa [ 1010 ]; // 定义父亲
int n , m , k ;
struct edge {
int u , v , w ;
};
int l ;
edge g [ 10010 ];
void add ( int u , int v , int w ) {
l ++ ;
g [ l ]. u = u ;
g [ l ]. v = v ;
g [ l ]. w = w ;
}
// 标准并查集
int findroot ( int x ) { return fa [ x ] == x ? x : fa [ x ] = findroot ( fa [ x ]); }
void Merge ( int x , int y ) {
x = findroot ( x );
y = findroot ( y );
fa [ x ] = y ;
}
bool cmp ( edge A , edge B ) { return A . w < B . w ; }
// Kruskal 算法
void kruskal () {
int tot = 0 ; // 存已选了的边数
int ans = 0 ; // 存总的代价
for ( int i = 1 ; i <= m ; i ++ ) {
int xr = findroot ( g [ i ]. u ), yr = findroot ( g [ i ]. v );
if ( xr != yr ) { // 如果父亲不一样
Merge ( xr , yr ); // 合并
tot ++ ; // 边数增加
ans += g [ i ]. w ; // 代价增加
if ( tot == n - k ) { // 检查选的边数是否满足 k 个棉花糖
cout << ans << '\n' ;
return ;
}
}
}
cout << "No Answer \n " ; // 无法连成
}
int main () {
cin >> n >> m >> k ;
if ( n == k ) { // 特判边界情况
cout << "0 \n " ;
return 0 ;
}
for ( int i = 1 ; i <= n ; i ++ ) { // 初始化
fa [ i ] = i ;
}
for ( int i = 1 ; i <= m ; i ++ ) {
int u , v , w ;
cin >> u >> v >> w ;
add ( u , v , w ); // 添加边
}
sort ( g + 1 , g + m + 1 , cmp ); // 先按边权排序
kruskal ();
return 0 ;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58 class Edge :
def __init__ ( self , u , v , w ):
self . u = u
self . v = v
self . w = w
fa = [ 0 ] * 1010 # 定义父亲
g = []
def add ( u , v , w ):
g . append ( Edge ( u , v , w ))
# 标准并查集
def findroot ( x ):
if fa [ x ] == x :
return x
fa [ x ] = findroot ( fa [ x ])
return fa [ x ]
def Merge ( x , y ):
x = findroot ( x )
y = findroot ( y )
fa [ x ] = y
# Kruskal 算法
def kruskal ():
tot = 0 # 存已选了的边数
ans = 0 # 存总的代价
for e in g :
x = findroot ( e . u )
y = findroot ( e . v )
if x != y : # 如果父亲不一样
fa [ x ] = y # 合并
tot += 1 # 边数增加
ans += e . w # 代价增加
if tot == n - k : # 检查选的边数是否满足 k 个棉花糖
print ( ans )
return
print ( "No Answer" ) # 无法连成
if __name__ == "__main__" :
n , m , k = map ( int , input () . split ())
if n == k : # 特判边界情况
print ( "0" )
exit ()
for i in range ( 1 , n + 1 ): # 初始化
fa [ i ] = i
for i in range ( 1 , m + 1 ):
u , v , w = map ( int , input () . split ())
add ( u , v , w ) # 添加边
g . sort ( key = lambda edge : edge . w ) # 先按边权排序
kruskal ()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91 import java.util.Arrays ;
import java.util.Scanner ;
class Edge {
int u ;
int v ;
int w ;
Edge ( int u , int v , int w ) {
this . u = u ;
this . v = v ;
this . w = w ;
}
}
public class Main {
static int [] parent = new int [ 1010 ] ; // 定义父亲
static int m , n , k ; // n 表示点的数量, m 表示边的数量,k 表示需要的棉花糖个数
static Edge [] edges = new Edge [ 10010 ] ;
static int l ;
static void addEdge ( int u , int v , int w ) {
edges [++ l ] = new Edge ( u , v , w );
}
// 标准并查集
static int findroot ( int x ) {
if ( parent [ x ] != x ) {
parent [ x ] = findroot ( parent [ x ] );
}
return parent [ x ] ;
}
static void Merge ( int x , int y ) {
x = findroot ( x );
y = findroot ( y );
parent [ x ] = y ;
}
static boolean cmp ( Edge A , Edge B ) {
return A . w < B . w ;
}
// Kruskal 算法
static void kruskal () {
int tot = 0 ; // 存已选了的边数
int ans = 0 ; // 存总的代价
for ( int i = 1 ; i <= m ; i ++ ) {
int xr = findroot ( edges [ i ] . u );
int yr = findroot ( edges [ i ] . v );
if ( xr != yr ) { // 如果父亲不一样
Merge ( xr , yr ); // 合并
tot ++ ; // 边数增加
ans += edges [ i ] . w ; // 代价增加
if ( tot == n - k ) { // 检查选的边数是否满足 k 个棉花糖
System . out . println ( ans );
return ;
}
}
}
System . out . println ( "No Answer" ); // 无法连成
}
public static void main ( String [] args ) {
Scanner scanner = new Scanner ( System . in );
n = scanner . nextInt ();
m = scanner . nextInt ();
k = scanner . nextInt ();
if ( n == k ) { // 特判边界情况
System . out . println ( "0" );
return ;
}
// 初始化
for ( int i = 1 ; i <= n ; i ++ ) {
parent [ i ] = i ;
}
for ( int i = 1 ; i <= m ; i ++ ) {
int u = scanner . nextInt ();
int v = scanner . nextInt ();
int w = scanner . nextInt ();
addEdge ( u , v , w ); // 添加边
}
Arrays . sort ( edges , 1 , m + 1 , ( a , b ) -> Integer . compare ( a . w , b . w )); // 先按边权排序
kruskal ();
scanner . close ();
}
}
Prim 算法 Prim 算法是另一种常见并且好写的最小生成树算法.该算法的基本思想是从一个结点开始,不断加点(而不是 Kruskal 算法的加边).
实现 图示:
具体来说,每次要选择距离最小的一个结点,以及用新的边更新其他结点的距离.
其实跟 Dijkstra 算法一样,每次找到距离最小的一个点,可以暴力找也可以用堆维护.
堆优化的方式类似 Dijkstra 的堆优化,但如果使用二叉堆等不支持 𝑂 ( 1 ) O ( 1 ) 不一定 实际跑得更快.
暴力:𝑂 ( 𝑛 2 + 𝑚 ) O ( n 2 + m )
二叉堆:𝑂 ( ( 𝑛 + 𝑚 ) l o g 𝑛 ) O ( ( n + m ) log n )
Fib 堆:𝑂 ( 𝑛 l o g 𝑛 + 𝑚 ) O ( n log n + m )
伪代码:
1 𝐈 𝐧 𝐩 𝐮 𝐭 . T h e n o d e s o f t h e g r a p h 𝑉 ; t h e f u n c t i o n 𝑔 ( 𝑢 , 𝑣 ) w h i c h m e a n s t h e w e i g h t o f t h e e d g e ( 𝑢 , 𝑣 ) ; t h e f u n c t i o n 𝑎 𝑑 𝑗 ( 𝑣 ) w h i c h m e a n s t h e n o d e s a d j a c e n t t o 𝑣 . 2 𝐎 𝐮 𝐭 𝐩 𝐮 𝐭 . T h e s u m o f w e i g h t s o f t h e M S T o f t h e i n p u t g r a p h . 3 𝐌 𝐞 𝐭 𝐡 𝐨 𝐝 . 4 𝑟 𝑒 𝑠 𝑢 𝑙 𝑡 ← 0 5 c h o o s e a n a r b i t r a r y n o d e i n 𝑉 t o b e t h e 𝑟 𝑜 𝑜 𝑡 6 𝑑 𝑖 𝑠 ( 𝑟 𝑜 𝑜 𝑡 ) ← 0 7 𝐟 𝐨 𝐫 e a c h n o d e 𝑣 ∈ ( 𝑉 − { 𝑟 𝑜 𝑜 𝑡 } ) 8 𝑑 𝑖 𝑠 ( 𝑣 ) ← ∞ 9 𝑟 𝑒 𝑠 𝑡 ← 𝑉 1 0 𝐰 𝐡 𝐢 𝐥 𝐞 𝑟 𝑒 𝑠 𝑡 ≠ ∅ 1 1 𝑐 𝑢 𝑟 ← t h e n o d e w i t h t h e m i n i m u m 𝑑 𝑖 𝑠 i n 𝑟 𝑒 𝑠 𝑡 1 2 𝑟 𝑒 𝑠 𝑢 𝑙 𝑡 ← 𝑟 𝑒 𝑠 𝑢 𝑙 𝑡 + 𝑑 𝑖 𝑠 ( 𝑐 𝑢 𝑟 ) 1 3 𝑟 𝑒 𝑠 𝑡 ← 𝑟 𝑒 𝑠 𝑡 − { 𝑐 𝑢 𝑟 } 1 4 𝐟 𝐨 𝐫 e a c h n o d e 𝑣 ∈ 𝑎 𝑑 𝑗 ( 𝑐 𝑢 𝑟 ) 1 5 𝑑 𝑖 𝑠 ( 𝑣 ) ← m i n ( 𝑑 𝑖 𝑠 ( 𝑣 ) , 𝑔 ( 𝑐 𝑢 𝑟 , 𝑣 ) ) 1 6 𝐫 𝐞 𝐭 𝐮 𝐫 𝐧 𝑟 𝑒 𝑠 𝑢 𝑙 𝑡 1 Input. The nodes of the graph V ; the function g ( u , v ) which means the weight of the edge ( u , v ) ; the function a d j ( v ) which means the nodes adjacent to v . 2 Output. The sum of weights of the MST of the input graph. 3 Method. 4 r e s u l t ← 0 5 choose an arbitrary node in V to be the r o o t 6 d i s ( r o o t ) ← 0 7 for each node v ∈ ( V − { r o o t } ) 8 d i s ( v ) ← ∞ 9 r e s t ← V 10 while r e s t ≠ ∅ 11 c u r ← the node with the minimum d i s in r e s t 12 r e s u l t ← r e s u l t + d i s ( c u r ) 13 r e s t ← r e s t − { c u r } 14 for each node v ∈ a d j ( c u r ) 15 d i s ( v ) ← min ( d i s ( v ) , g ( c u r , v ) ) 16 return r e s u l t 注意:上述代码只是求出了最小生成树的权值,如果要输出方案还需要记录每个点的 𝑑 𝑖 𝑠 d i s
代码实现 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60 // 使用二叉堆优化的 Prim 算法.
#include <cstring>
#include <iostream>
#include <queue>
using namespace std ;
constexpr int N = 5050 , M = 2e5 + 10 ;
struct E {
int v , w , x ;
} e [ M * 2 ];
int n , m , h [ N ], cnte ;
void adde ( int u , int v , int w ) { e [ ++ cnte ] = E { v , w , h [ u ]}, h [ u ] = cnte ; }
struct S {
int u , d ;
};
bool operator < ( const S & x , const S & y ) { return x . d > y . d ; }
priority_queue < S > q ;
int dis [ N ];
bool vis [ N ];
int res = 0 , cnt = 0 ;
void Prim () {
memset ( dis , 0x3f , sizeof ( dis ));
dis [ 1 ] = 0 ;
q . push ({ 1 , 0 });
while ( ! q . empty ()) {
if ( cnt >= n ) break ;
int u = q . top (). u , d = q . top (). d ;
q . pop ();
if ( vis [ u ]) continue ;
vis [ u ] = true ;
++ cnt ;
res += d ;
for ( int i = h [ u ]; i ; i = e [ i ]. x ) {
int v = e [ i ]. v , w = e [ i ]. w ;
if ( w < dis [ v ]) {
dis [ v ] = w , q . push ({ v , w });
}
}
}
}
int main () {
cin >> n >> m ;
for ( int i = 1 , u , v , w ; i <= m ; ++ i ) {
cin >> u >> v >> w , adde ( u , v , w ), adde ( v , u , w );
}
Prim ();
if ( cnt == n )
cout << res ;
else
cout << "No MST." ;
return 0 ;
}
证明 从任意一个结点开始,将结点分成两类:已加入的,未加入的.
每次从未加入的结点中,找一个与已加入的结点之间边权最小值最小的结点.
然后将这个结点加入,并连上那条边权最小的边.
重复 𝑛 − 1 n − 1
证明:还是说明在每一步,都存在一棵最小生成树包含已选边集.
基础:只有一个结点的时候,显然成立.
归纳:如果某一步成立,当前边集为 𝐹 F 𝑇 T 𝑒 e
如果 𝑒 e 𝑇 T
否则考虑 𝑇 + 𝑒 T + e 𝑓 f
首先,𝑓 f 𝑒 e 𝑓 f 𝑒 e
然后,𝑓 f 𝑒 e 𝑇 + 𝑒 − 𝑓 T + e − f
因此,𝑒 e 𝑓 f 𝑇 + 𝑒 − 𝑓 T + e − f 𝐹 F
Boruvka 算法 接下来介绍另一种求解最小生成树的算法——Boruvka 算法.该算法的思想是前两种算法的结合.它可以用于求解无向图的最小生成森林.(无向连通图就是最小生成树.)
在边具有较多特殊性质的问题中,Boruvka 算法具有优势.例如 CF888G 的完全图问题.
为了描述该算法,我们需要引入一些定义:
定义 𝐸 ′ E ′ 𝐸 ′ E ′ 连通块 表示一个点集 𝑉 ′ ⊆ 𝑉 V ′ ⊆ V 𝑢 u 𝑣 v 𝐸 ′ E ′ 定义一个连通块的 最小边 为它连向其它连通块的边中权值最小的那一条. 初始时,𝐸 ′ = ∅ E ′ = ∅
计算每个点分别属于哪个连通块.将每个连通块都设为「没有最小边」. 遍历每条边 ( 𝑢 , 𝑣 ) ( u , v ) 𝑢 u 𝑣 v 𝑢 u 𝑣 v 如果所有连通块都没有最小边,退出程序,此时的 𝐸 ′ E ′ 𝐸 ′ E ′ 下面通过一张动态图来举一个例子(图源自 维基百科 ):
当原图连通时,每次迭代连通块数量至少减半,算法只会迭代不超过 𝑂 ( l o g 𝑉 ) O ( log V ) 𝑂 ( 𝐸 l o g 𝑉 ) O ( E log V ) 维基百科 )
1 𝐈 𝐧 𝐩 𝐮 𝐭 . A g r a p h 𝐺 w h o s e e d g e s h a v e d i s t i n c t w e i g h t s . 2 𝐎 𝐮 𝐭 𝐩 𝐮 𝐭 . T h e m i n i m u m s p a n n i n g f o r e s t o f 𝐺 . 3 𝐌 𝐞 𝐭 𝐡 𝐨 𝐝 . 4 I n i t i a l i z e a f o r e s t 𝐹 t o b e a s e t o f o n e - v e r t e x t r e e s 5 𝐰 𝐡 𝐢 𝐥 𝐞 T r u e 6 F i n d t h e c o m p o n e n t s o f 𝐹 a n d l a b e l e a c h v e r t e x o f 𝐺 b y i t s c o m p o n e n t 7 I n i t i a l i z e t h e c h e a p e s t e d g e f o r e a c h c o m p o n e n t t o " N o n e " 8 𝐟 𝐨 𝐫 e a c h e d g e ( 𝑢 , 𝑣 ) o f 𝐺 9 𝐢 𝐟 𝑢 a n d 𝑣 h a v e d i f f e r e n t c o m p o n e n t l a b e l s 1 0 𝐢 𝐟 ( 𝑢 , 𝑣 ) i s c h e a p e r t h a n t h e c h e a p e s t e d g e f o r t h e c o m p o n e n t o f 𝑢 1 1 S e t ( 𝑢 , 𝑣 ) a s t h e c h e a p e s t e d g e f o r t h e c o m p o n e n t o f 𝑢 1 2 𝐢 𝐟 ( 𝑢 , 𝑣 ) i s c h e a p e r t h a n t h e c h e a p e s t e d g e f o r t h e c o m p o n e n t o f 𝑣 1 3 S e t ( 𝑢 , 𝑣 ) a s t h e c h e a p e s t e d g e f o r t h e c o m p o n e n t o f 𝑣 1 4 𝐢 𝐟 a l l c o m p o n e n t s ' c h e a p e s t e d g e s a r e " N o n e " 1 5 𝐫 𝐞 𝐭 𝐮 𝐫 𝐧 𝐹 1 6 𝐟 𝐨 𝐫 e a c h c o m p o n e n t w h o s e c h e a p e s t e d g e i s n o t " N o n e " 1 7 A d d i t s c h e a p e s t e d g e t o 𝐹 1 Input. A graph G whose edges have distinct weights. 2 Output. The minimum spanning forest of G . 3 Method. 4 Initialize a forest F to be a set of one-vertex trees 5 while True 6 Find the components of F and label each vertex of G by its component 7 Initialize the cheapest edge for each component to "None" 8 for each edge ( u , v ) of G 9 if u and v have different component labels 10 if ( u , v ) is cheaper than the cheapest edge for the component of u 11 Set ( u , v ) as the cheapest edge for the component of u 12 if ( u , v ) is cheaper than the cheapest edge for the component of v 13 Set ( u , v ) as the cheapest edge for the component of v 14 if all components'cheapest edges are "None" 15 return F 16 for each component whose cheapest edge is not "None" 17 Add its cheapest edge to F 需要注意边与边的比较通常需要第二关键字(例如按编号排序),以便当边权相同时分出边的大小.
习题 最小生成树的唯一性 考虑最小生成树的唯一性.如果一条边 不在最小生成树的边集中 ,并且可以替换与其 权值相同、并且在最小生成树边集 的另一条边.那么,这个最小生成树就是不唯一的.
对于 Kruskal 算法,只要计算为当前权值的边可以放几条,实际放了几条,如果这两个值不一样,那么就说明这几条边与之前的边产生了一个环(这个环中至少有两条当前权值的边,否则根据并查集,这条边是不能放的),即最小生成树不唯一.
寻找权值与当前边相同的边,我们只需要记录头尾指针,用单调队列即可在 𝑂 ( 𝛼 ( 𝑚 ) ) O ( α ( m ) )
例题:POJ 1679 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62 #include <algorithm>
#include <iostream>
struct Edge {
int x , y , z ;
};
int f [ 100001 ];
Edge a [ 100001 ];
int cmp ( const Edge & a , const Edge & b ) { return a . z < b . z ; }
int find ( int x ) { return f [ x ] == x ? x : f [ x ] = find ( f [ x ]); }
using std :: cin ;
using std :: cout ;
int main () {
cin . tie ( nullptr ) -> sync_with_stdio ( false );
int t ;
cin >> t ;
while ( t -- ) {
int n , m ;
cin >> n >> m ;
for ( int i = 1 ; i <= n ; i ++ ) f [ i ] = i ;
for ( int i = 1 ; i <= m ; i ++ ) cin >> a [ i ]. x >> a [ i ]. y >> a [ i ]. z ;
std :: sort ( a + 1 , a + m + 1 , cmp ); // 先排序
int num = 0 , ans = 0 , tail = 0 , sum1 = 0 , sum2 = 0 ;
bool flag = true ;
for ( int i = 1 ; i <= m + 1 ; i ++ ) { // 再并查集加边
if ( i > tail ) {
if ( sum1 != sum2 ) {
flag = false ;
break ;
}
sum1 = 0 ;
for ( int j = i ; j <= m + 1 ; j ++ ) {
if ( j > m || a [ j ]. z != a [ i ]. z ) {
tail = j - 1 ;
break ;
}
if ( find ( a [ j ]. x ) != find ( a [ j ]. y )) ++ sum1 ;
}
sum2 = 0 ;
}
if ( i > m ) break ;
int x = find ( a [ i ]. x );
int y = find ( a [ i ]. y );
if ( x != y && num != n - 1 ) {
sum2 ++ ;
num ++ ;
f [ x ] = f [ y ];
ans += a [ i ]. z ;
}
}
if ( flag )
cout << ans << '\n' ;
else
cout << "Not Unique! \n " ;
}
return 0 ;
}
次小生成树 非严格次小生成树 定义 在无向图中,边权和最小的满足边权和 大于等于 最小生成树边权和的生成树
求解方法 求出无向图的最小生成树 𝑇 T 𝑀 M 遍历每条未被选中的边 𝑒 = ( 𝑢 , 𝑣 , 𝑤 ) e = ( u , v , w ) 𝑇 T 𝑢 u 𝑣 v 𝑒 ′ = ( 𝑠 , 𝑡 , 𝑤 ′ ) e ′ = ( s , t , w ′ ) 𝑇 T 𝑒 e 𝑒 ′ e ′ 𝑀 ′ = 𝑀 + 𝑤 − 𝑤 ′ M ′ = M + w − w ′ 𝑇 ′ T ′ 对所有替换得到的答案 𝑀 ′ M ′ 如何求 𝑢 , 𝑣 u , v
我们可以使用倍增来维护,预处理出每个节点的 2 𝑖 2 i 2 𝑖 2 i
严格次小生成树 定义 在无向图中,边权和最小的满足边权和 严格大于 最小生成树边权和的生成树
求解方法 考虑刚才的非严格次小生成树求解过程,为什么求得的解是非严格的?
因为最小生成树保证生成树中 𝑢 u 𝑣 v 不大于 其他从 𝑢 u 𝑣 v
解决的办法很自然:我们维护到 2 𝑖 2 i 严格次大边权 ,当用于替换的边的权值与原生成树中路径最大边权相等时,我们用严格次大值来替换即可.
这个过程可以用倍增求解,复杂度 𝑂 ( 𝑚 l o g 𝑚 ) O ( m log m )
代码实现 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154 #include <algorithm>
#include <iostream>
constexpr int INF = 0x3fffffff ;
constexpr long long INF64 = 0x3fffffffffffffffLL ;
struct Edge {
int u , v , val ;
bool operator < ( const Edge & other ) const { return val < other . val ; }
};
Edge e [ 300010 ];
bool used [ 300010 ];
int n , m ;
long long sum ;
class Tr {
private :
struct Edge {
int to , nxt , val ;
} e [ 600010 ];
int cnt , head [ 100010 ];
int pnt [ 100010 ][ 22 ];
int dpth [ 100010 ];
// 到祖先的路径上边权最大的边
int maxx [ 100010 ][ 22 ];
// 到祖先的路径上边权次大的边,若不存在则为 -INF
int minn [ 100010 ][ 22 ];
public :
void addedge ( int u , int v , int val ) {
e [ ++ cnt ] = Edge { v , head [ u ], val };
head [ u ] = cnt ;
}
void insedge ( int u , int v , int val ) {
addedge ( u , v , val );
addedge ( v , u , val );
}
void dfs ( int now , int fa ) {
dpth [ now ] = dpth [ fa ] + 1 ;
pnt [ now ][ 0 ] = fa ;
minn [ now ][ 0 ] = - INF ;
for ( int i = 1 ; ( 1 << i ) <= dpth [ now ]; i ++ ) {
pnt [ now ][ i ] = pnt [ pnt [ now ][ i - 1 ]][ i - 1 ];
int kk [ 4 ] = { maxx [ now ][ i - 1 ], maxx [ pnt [ now ][ i - 1 ]][ i - 1 ],
minn [ now ][ i - 1 ], minn [ pnt [ now ][ i - 1 ]][ i - 1 ]};
// 从四个值中取得最大值
std :: sort ( kk , kk + 4 );
maxx [ now ][ i ] = kk [ 3 ];
// 取得严格次大值
int ptr = 2 ;
while ( ptr >= 0 && kk [ ptr ] == kk [ 3 ]) ptr -- ;
minn [ now ][ i ] = ( ptr == -1 ? - INF : kk [ ptr ]);
}
for ( int i = head [ now ]; i ; i = e [ i ]. nxt ) {
if ( e [ i ]. to != fa ) {
maxx [ e [ i ]. to ][ 0 ] = e [ i ]. val ;
dfs ( e [ i ]. to , now );
}
}
}
int lca ( int a , int b ) {
if ( dpth [ a ] < dpth [ b ]) std :: swap ( a , b );
for ( int i = 21 ; i >= 0 ; i -- )
if ( dpth [ pnt [ a ][ i ]] >= dpth [ b ]) a = pnt [ a ][ i ];
if ( a == b ) return a ;
for ( int i = 21 ; i >= 0 ; i -- ) {
if ( pnt [ a ][ i ] != pnt [ b ][ i ]) {
a = pnt [ a ][ i ];
b = pnt [ b ][ i ];
}
}
return pnt [ a ][ 0 ];
}
int query ( int a , int b , int val ) {
int res = - INF ;
for ( int i = 21 ; i >= 0 ; i -- ) {
if ( dpth [ pnt [ a ][ i ]] >= dpth [ b ]) {
if ( val != maxx [ a ][ i ])
res = std :: max ( res , maxx [ a ][ i ]);
else
res = std :: max ( res , minn [ a ][ i ]);
a = pnt [ a ][ i ];
}
}
return res ;
}
} tr ;
int fa [ 100010 ];
int find ( int x ) { return fa [ x ] == x ? x : fa [ x ] = find ( fa [ x ]); }
void Kruskal () {
int tot = 0 ;
std :: sort ( e + 1 , e + m + 1 );
for ( int i = 1 ; i <= n ; i ++ ) fa [ i ] = i ;
for ( int i = 1 ; i <= m ; i ++ ) {
int a = find ( e [ i ]. u );
int b = find ( e [ i ]. v );
if ( a != b ) {
fa [ a ] = b ;
tot ++ ;
tr . insedge ( e [ i ]. u , e [ i ]. v , e [ i ]. val );
sum += e [ i ]. val ;
used [ i ] = true ;
}
if ( tot == n - 1 ) break ;
}
}
int main () {
std :: ios :: sync_with_stdio ( false );
std :: cin . tie ( nullptr );
std :: cin >> n >> m ;
for ( int i = 1 ; i <= m ; i ++ ) {
int u , v , val ;
std :: cin >> u >> v >> val ;
e [ i ] = Edge { u , v , val };
}
Kruskal ();
long long ans = INF64 ;
tr . dfs ( 1 , 0 );
for ( int i = 1 ; i <= m ; i ++ ) {
if ( ! used [ i ]) {
int _lca = tr . lca ( e [ i ]. u , e [ i ]. v );
// 找到路径上不等于 e[i].val 的最大边权
long long tmpa = tr . query ( e [ i ]. u , _lca , e [ i ]. val );
long long tmpb = tr . query ( e [ i ]. v , _lca , e [ i ]. val );
// 这样的边可能不存在,只在这样的边存在时更新答案
if ( std :: max ( tmpa , tmpb ) > - INF )
ans = std :: min ( ans , sum - std :: max ( tmpa , tmpb ) + e [ i ]. val );
}
}
// 次小生成树不存在时输出 -1
std :: cout << ( ans == INF64 ? -1 : ans ) << '\n' ;
return 0 ;
}
瓶颈生成树 定义 无向图 𝐺 G 𝐺 G
性质 最小生成树是瓶颈生成树的充分不必要条件. 即最小生成树一定是瓶颈生成树,而瓶颈生成树不一定是最小生成树.
关于最小生成树一定是瓶颈生成树这一命题,可以运用反证法证明:我们设最小生成树中的最大边权为 𝑤 w 𝑤 w
例题 POJ 2395 Out of Hay 给出 n 个农场和 m 条边,农场按 1 到 n 编号,现在有一人要从编号为 1 的农场出发到其他的农场去,求在这途中他最多需要携带的水的重量,注意他每到达一个农场,可以对水进行补给,且要使总共的路径长度最小. 题目要求的就是瓶颈树的最大边,可以通过求最小生成树来解决.
最小瓶颈路 定义 无向图 𝐺 G
性质 根据最小生成树定义,x 到 y 的最小瓶颈路上的最大边权等于最小生成树上 x 到 y 路径上的最大边权.虽然最小生成树不唯一,但是每种最小生成树 x 到 y 路径的最大边权相同且为最小值.也就是说,每种最小生成树上的 x 到 y 的路径均为最小瓶颈路.
但是,并不是所有最小瓶颈路都存在一棵最小生成树满足其为树上 x 到 y 的简单路径.
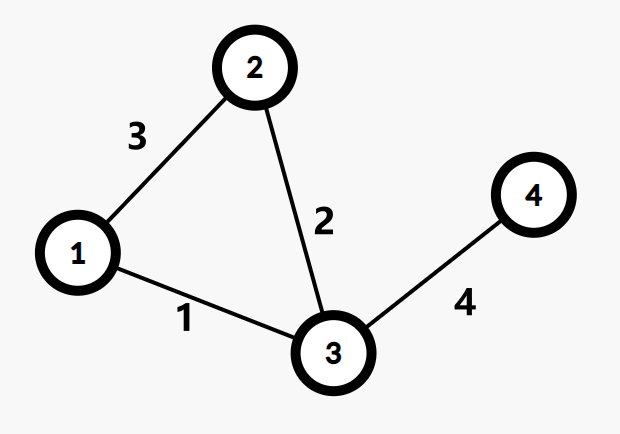
例如下图:
1 到 4 的最小瓶颈路显然有以下两条:1-2-3-4.1-3-4.
但是,1-2 不会出现在任意一种最小生成树上.
应用 由于最小瓶颈路不唯一,一般情况下会询问最小瓶颈路上的最大边权.
也就是说,我们需要求最小生成树链上的 max.
倍增、树剖都可以解决,这里不再展开.
Kruskal 重构树 定义 在跑 Kruskal 的过程中我们会从小到大加入若干条边.现在我们仍然按照这个顺序.
首先新建 𝑛 n 0 0
每一次加边会合并两个集合,我们可以新建一个点,点权为加入边的边权,同时将两个集合的根节点分别设为新建点的左儿子和右儿子.然后我们将两个集合和新建点合并成一个集合.将新建点设为根.
不难发现,在进行 𝑛 − 1 n − 1 𝑛 n
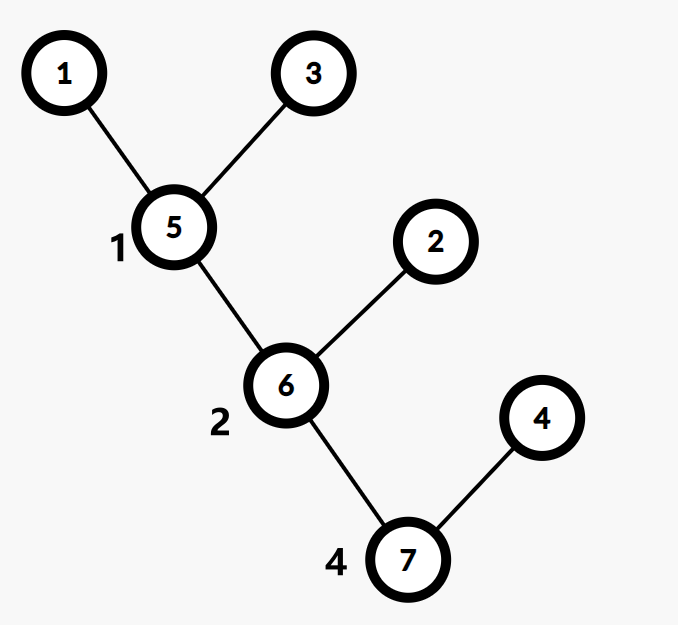
举个例子:
这张图的 Kruskal 重构树如下:
性质 不难发现,原图中两个点之间的所有简单路径上最大边权的最小值 = 最小生成树上两个点之间的简单路径上的最大值 = Kruskal 重构树上两点之间的 LCA 的权值.
也就是说,到点 𝑥 x ≤ 𝑣 𝑎 𝑙 ≤ v a l 𝑦 y
我们在 Kruskal 重构树上找到 𝑥 x ≤ 𝑣 𝑎 𝑙 ≤ v a l
如果需要求原图中两个点之间的所有简单路径上最小边权的最大值,则在跑 Kruskal 的过程中按边权大到小的顺序加边.
「LOJ 137」最小瓶颈路 加强版 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138 #include <algorithm>
#include <iostream>
using namespace std ;
constexpr int MAX_VAL_RANGE = 280010 ;
int n , m , log2Values [ MAX_VAL_RANGE + 1 ];
namespace TR {
struct Edge {
int to , nxt , val ;
} e [ 400010 ];
int cnt , head [ 140010 ];
void addedge ( int u , int v , int val = 0 ) {
e [ ++ cnt ] = Edge { v , head [ u ], val };
head [ u ] = cnt ;
}
int val [ 140010 ];
namespace LCA {
int sec [ 280010 ], cnt ;
int pos [ 140010 ];
int dpth [ 140010 ];
void dfs ( int now , int fa ) {
dpth [ now ] = dpth [ fa ] + 1 ;
sec [ ++ cnt ] = now ;
pos [ now ] = cnt ;
for ( int i = head [ now ]; i ; i = e [ i ]. nxt ) {
if ( fa != e [ i ]. to ) {
dfs ( e [ i ]. to , now );
sec [ ++ cnt ] = now ;
}
}
}
int dp [ 280010 ][ 20 ];
void init () {
dfs ( 2 * n - 1 , 0 );
for ( int i = 1 ; i <= 4 * n ; i ++ ) {
dp [ i ][ 0 ] = sec [ i ];
}
for ( int j = 1 ; j <= 19 ; j ++ ) {
for ( int i = 1 ; i + ( 1 << j ) - 1 <= 4 * n ; i ++ ) {
dp [ i ][ j ] = dpth [ dp [ i ][ j - 1 ]] < dpth [ dp [ i + ( 1 << ( j - 1 ))][ j - 1 ]]
? dp [ i ][ j - 1 ]
: dp [ i + ( 1 << ( j - 1 ))][ j - 1 ];
}
}
}
int lca ( int x , int y ) {
int l = pos [ x ], r = pos [ y ];
if ( l > r ) {
swap ( l , r );
}
int k = log2Values [ r - l + 1 ];
return dpth [ dp [ l ][ k ]] < dpth [ dp [ r - ( 1 << k ) + 1 ][ k ]]
? dp [ l ][ k ]
: dp [ r - ( 1 << k ) + 1 ][ k ];
}
} // namespace LCA
} // namespace TR
using TR :: addedge ;
namespace GR {
struct Edge {
int u , v , val ;
bool operator < ( const Edge & other ) const { return val < other . val ; }
} e [ 100010 ];
int fa [ 140010 ];
int find ( int x ) { return fa [ x ] == 0 ? x : fa [ x ] = find ( fa [ x ]); }
void kruskal () { // 最小生成树
int tot = 0 , cnt = n ;
sort ( e + 1 , e + m + 1 );
for ( int i = 1 ; i <= m ; i ++ ) {
int fau = find ( e [ i ]. u ), fav = find ( e [ i ]. v );
if ( fau != fav ) {
cnt ++ ;
fa [ fau ] = fa [ fav ] = cnt ;
addedge ( fau , cnt );
addedge ( cnt , fau );
addedge ( fav , cnt );
addedge ( cnt , fav );
TR :: val [ cnt ] = e [ i ]. val ;
tot ++ ;
}
if ( tot == n - 1 ) {
break ;
}
}
}
} // namespace GR
int ans ;
int A , B , C , P ;
int rnd () { return A = ( A * B + C ) % P ; }
void initLog2 () {
for ( int i = 2 ; i <= MAX_VAL_RANGE ; i ++ ) {
log2Values [ i ] = log2Values [ i >> 1 ] + 1 ;
}
}
int main () {
initLog2 (); // 预处理
cin >> n >> m ;
for ( int i = 1 ; i <= m ; i ++ ) {
int u , v , val ;
cin >> u >> v >> val ;
GR :: e [ i ] = GR :: Edge { u , v , val };
}
GR :: kruskal ();
TR :: LCA :: init ();
int Q ;
cin >> Q ;
cin >> A >> B >> C >> P ;
while ( Q -- ) {
int u = rnd () % n + 1 , v = rnd () % n + 1 ;
ans += TR :: val [ TR :: LCA :: lca ( u , v )];
ans %= 1000000007 ;
}
cout << ans ;
return 0 ;
}
NOI 2018 归程 首先预处理出来每一个点到根节点的最短路.
我们构造出来根据海拔的最大生成树.显然每次询问可以到达的节点是在最大生成树中和询问点的路径上最小边权 > 𝑝 > p
根据 Kruskal 重构树的性质,这些节点满足均在一棵子树内同时为其所有叶子节点.
也就是说,我们只需要求出 Kruskal 重构树上每一棵子树叶子的权值 min 就可以支持子树询问.
询问的根节点可以使用 Kruskal 重构树上倍增的方式求出.
时间复杂度 𝑂 ( ( 𝑛 + 𝑚 + 𝑄 ) l o g 𝑛 ) O ( ( n + m + Q ) log n )
2026/1/7 08:56:54 ,更新历史 在 GitHub 上编辑此页! Ir1d , ouuan , sshwy , zhouyuyang2002 , Enter-tainer , Marcythm , partychicken , bear-good , HeRaNO , billchenchina , diauweb , StudyingFather , Tiphereth-A , abc1763613206 , Chrogeek , greyqz , Hszzzx , renbaoshuo , ShadowsEpic , stevebraveman , toprise , Xeonacid , y-kx-b , ayuusweetfish , Backl1ght , c-forrest , CCXXXI , Fomalhauthmj , Haohu Shen , Henry-ZHR , kawa-yoiko , kenlig , ksyx , Menci , mgt , nalemy , silvecor , xzdeyg , ylxmf2005 , YOYO-UIAT , yzxoi , zirnc CC BY-SA 4.0 和 SATA 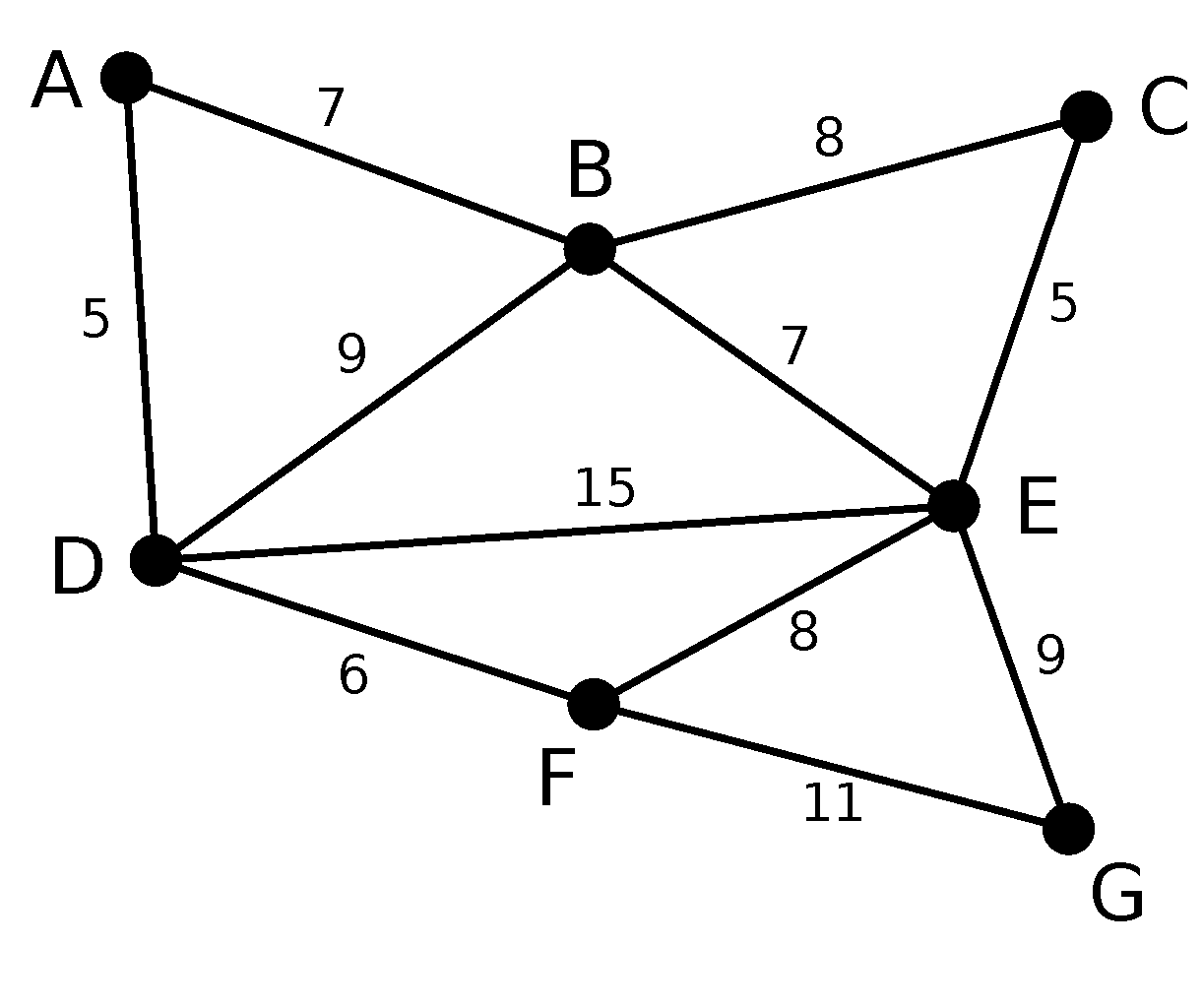
 \\
& \text{ denoting that there is an edge between } u \text{ and } v \text{ weighted } w . \\
2 & \textbf{Output. } \text{The edges of the MST of the input graph}.\\
3 & \textbf{Method. } \\
4 & result \gets \varnothing \\
5 & \text{sort } e \text{ into nondecreasing order by weight } w \\
6 & \textbf{for} \text{ each } (u, v, w) \text{ in the sorted } e \\
7 & \qquad \textbf{if } u \text{ and } v \text{ are not connected in the union-find set } \\
8 & \qquad\qquad \text{connect } u \text{ and } v \text{ in the union-find set} \\
9 & \qquad\qquad result \gets result\;\bigcup\ \{(u, v, w)\} \\
10 & \textbf{return } result
\end{array}")