最大流 本页面主要介绍最大流问题相关的算法知识.
概述 网络流基本概念参见 网络流简介 .
令 𝐺 = ( 𝑉 , 𝐸 ) G = ( V , E ) 𝐺 G 𝑓 f | 𝑓 | | f | ∑ 𝑥 ∈ 𝑉 𝑓 ( 𝑠 , 𝑥 ) − ∑ 𝑥 ∈ 𝑉 𝑓 ( 𝑥 , 𝑠 ) ∑ x ∈ V f ( s , x ) − ∑ x ∈ V f ( x , s )
Ford–Fulkerson 增广 Ford–Fulkerson 增广是计算最大流的一类算法的总称.该方法运用贪心的思想,通过寻找增广路来更新并求解最大流.
概述 给定网络 𝐺 G 𝐺 G 𝑓 f
对于边 ( 𝑢 , 𝑣 ) ( u , v ) 𝑐 𝑓 ( 𝑢 , 𝑣 ) c f ( u , v ) 𝑐 𝑓 ( 𝑢 , 𝑣 ) = 𝑐 ( 𝑢 , 𝑣 ) − 𝑓 ( 𝑢 , 𝑣 ) c f ( u , v ) = c ( u , v ) − f ( u , v )
我们将 𝐺 G 0 0 𝐺 𝑓 G f 𝐺 𝑓 = ( 𝑉 , 𝐸 𝑓 ) G f = ( V , E f ) 𝐸 𝑓 = { ( 𝑢 , 𝑣 ) ∣ 𝑐 𝑓 ( 𝑢 , 𝑣 ) > 0 } E f = { ( u , v ) ∣ c f ( u , v ) > 0 }
Warning 正如我们马上要提到的,流量可能是负值,因此,𝐸 𝑓 E f 𝐸 E
我们将 𝐺 𝑓 G f 𝑠 s 𝑡 t ( 𝑢 , 𝑣 ) ( u , v )
此外,在 Ford–Fulkerson 增广的过程中,对于每条边 ( 𝑢 , 𝑣 ) ( u , v ) ( 𝑣 , 𝑢 ) ( v , u ) 𝑓 ( 𝑢 , 𝑣 ) = − 𝑓 ( 𝑣 , 𝑢 ) f ( u , v ) = − f ( v , u ) 𝑓 ( 𝑢 , 𝑣 ) f ( u , v ) 𝑓 ( 𝑣 , 𝑢 ) f ( v , u )
Tip 在最大流算法的代码实现中,我们往往需要支持快速访问反向边的操作.在邻接矩阵中,这一操作是 trivial 的(𝑔 𝑢 , 𝑣 ↔ 𝑔 𝑣 , 𝑢 g u , v ↔ g v , u 0 0 𝑖 i 𝑖 ⊕ 1 i ⊕ 1
初次接触这一方法的读者可能察觉到一个违反直觉的情形——反向边的流量 𝑓 ( 𝑣 , 𝑢 ) f ( v , u ) 𝑐 𝑓 c f 𝑓 ( 𝑣 , 𝑢 ) f ( v , u ) 𝑐 𝑓 ( 𝑣 , 𝑢 ) c f ( v , u )
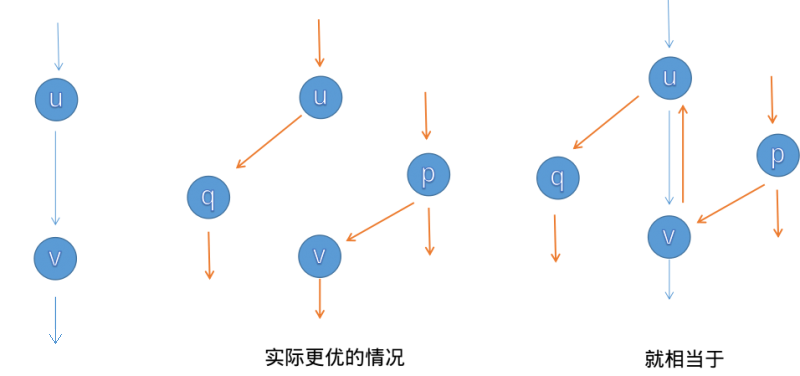
以下案例有可能帮助你理解这一过程.假设 𝐺 G
𝐺 G 𝑢 , 𝑣 u , v 1 1 我们注意到,如果进行中图上的增广,这个局部的最大流量不是 1 1 2 2 𝑢 u 𝑣 v 现在引入退流操作.第一次增广后,退流意味着 𝑐 𝑓 ( 𝑣 , 𝑢 ) c f ( v , u ) 1 1 ( 𝑣 , 𝑢 ) ( v , u ) 𝑝 , 𝑣 , 𝑢 , 𝑞 p , v , u , q ( 𝑢 , 𝑣 ) ( u , v )
以上案例告诉我们,退流操作带来的「抵消」效果使得我们无需担心我们按照「错误」的顺序选择了增广路.
容易发现,只要 𝐺 𝑓 G f
最大流最小割定理 我们大致了解了 Ford–Fulkerson 增广的思想,可是如何证明这一方法的正确性呢?为什么增广结束后的流 𝑓 f
实际上,Ford–Fulkerson 增广的正确性和最大流最小割定理(The Maxflow-Mincut Theorem)等价.这一定理指出,对于任意网络 𝐺 = ( 𝑉 , 𝐸 ) G = ( V , E ) 𝑓 f { 𝑆 , 𝑇 } { S , T } | 𝑓 | = | | 𝑆 , 𝑇 | | | f | = | | S , T | |
为了证明最大流最小割定理,我们先从一个引理出发:对于网络 𝐺 = ( 𝑉 , 𝐸 ) G = ( V , E ) 𝑓 f { 𝑆 , 𝑇 } { S , T } | 𝑓 | ≤ | | 𝑆 , 𝑇 | | | f | ≤ | | S , T | | { ( 𝑢 , 𝑣 ) | 𝑢 ∈ 𝑆 , 𝑣 ∈ 𝑇 } { ( u , v ) | u ∈ S , v ∈ T } { ( 𝑢 , 𝑣 ) | 𝑢 ∈ 𝑇 , 𝑣 ∈ 𝑆 } { ( u , v ) | u ∈ T , v ∈ S }
证明 | 𝑓 | = 𝑓 ( 𝑠 ) = ∑ 𝑢 ∈ 𝑆 𝑓 ( 𝑢 ) = ∑ 𝑢 ∈ 𝑆 ( ∑ 𝑣 ∈ 𝑉 𝑓 ( 𝑢 , 𝑣 ) − ∑ 𝑣 ∈ 𝑉 𝑓 ( 𝑣 , 𝑢 ) ) = ∑ 𝑢 ∈ 𝑆 ( ∑ 𝑣 ∈ 𝑇 𝑓 ( 𝑢 , 𝑣 ) + ∑ 𝑣 ∈ 𝑆 𝑓 ( 𝑢 , 𝑣 ) − ∑ 𝑣 ∈ 𝑇 𝑓 ( 𝑣 , 𝑢 ) − ∑ 𝑣 ∈ 𝑆 𝑓 ( 𝑣 , 𝑢 ) ) = ∑ 𝑢 ∈ 𝑆 ( ∑ 𝑣 ∈ 𝑇 𝑓 ( 𝑢 , 𝑣 ) − ∑ 𝑣 ∈ 𝑇 𝑓 ( 𝑣 , 𝑢 ) ) + ∑ 𝑢 ∈ 𝑆 ∑ 𝑣 ∈ 𝑆 𝑓 ( 𝑢 , 𝑣 ) − ∑ 𝑢 ∈ 𝑆 ∑ 𝑣 ∈ 𝑆 𝑓 ( 𝑣 , 𝑢 ) = ∑ 𝑢 ∈ 𝑆 ( ∑ 𝑣 ∈ 𝑇 𝑓 ( 𝑢 , 𝑣 ) − ∑ 𝑣 ∈ 𝑇 𝑓 ( 𝑣 , 𝑢 ) ) ≤ ∑ 𝑢 ∈ 𝑆 ∑ 𝑣 ∈ 𝑇 𝑓 ( 𝑢 , 𝑣 ) ≤ ∑ 𝑢 ∈ 𝑆 ∑ 𝑣 ∈ 𝑇 𝑐 ( 𝑢 , 𝑣 ) = | | 𝑆 , 𝑇 | | | f | = f ( s ) = ∑ u ∈ S f ( u ) = ∑ u ∈ S ( ∑ v ∈ V f ( u , v ) − ∑ v ∈ V f ( v , u ) ) = ∑ u ∈ S ( ∑ v ∈ T f ( u , v ) + ∑ v ∈ S f ( u , v ) − ∑ v ∈ T f ( v , u ) − ∑ v ∈ S f ( v , u ) ) = ∑ u ∈ S ( ∑ v ∈ T f ( u , v ) − ∑ v ∈ T f ( v , u ) ) + ∑ u ∈ S ∑ v ∈ S f ( u , v ) − ∑ u ∈ S ∑ v ∈ S f ( v , u ) = ∑ u ∈ S ( ∑ v ∈ T f ( u , v ) − ∑ v ∈ T f ( v , u ) ) ≤ ∑ u ∈ S ∑ v ∈ T f ( u , v ) ≤ ∑ u ∈ S ∑ v ∈ T c ( u , v ) = | | S , T | | 为了取等,第一个不等号需要 { ( 𝑢 , 𝑣 ) ∣ 𝑢 ∈ 𝑇 , 𝑣 ∈ 𝑆 } { ( u , v ) ∣ u ∈ T , v ∈ S } { ( 𝑢 , 𝑣 ) ∣ 𝑢 ∈ 𝑆 , 𝑣 ∈ 𝑇 } { ( u , v ) ∣ u ∈ S , v ∈ T }
那么,对于任意网络,以上取等条件是否总是能被满足呢?如果答案是肯定的,则最大流最小割定理得证.以下我们尝试证明.
证明 假设某一轮增广后,我们得到流 𝑓 f 𝐺 𝑓 G f 𝐺 𝑓 G f 𝑠 s 𝑡 t 𝑠 s 𝑆 S 𝑇 = 𝑉 ∖ 𝑆 T = V ∖ S
显然,{ 𝑆 , 𝑇 } { S , T } 𝐺 𝑓 G f | | 𝑆 , 𝑇 | | = ∑ 𝑢 ∈ 𝑆 ∑ 𝑣 ∈ 𝑇 𝑐 𝑓 ( 𝑢 , 𝑣 ) = 0 | | S , T | | = ∑ u ∈ S ∑ v ∈ T c f ( u , v ) = 0 𝑢 ∈ 𝑆 , 𝑣 ∈ 𝑇 , ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 u ∈ S , v ∈ T , ( u , v ) ∈ E f 𝑐 𝑓 ( 𝑢 , 𝑣 ) = 0 c f ( u , v ) = 0
( 𝑢 , 𝑣 ) ∈ 𝐸 ( u , v ) ∈ E 𝑐 𝑓 ( 𝑢 , 𝑣 ) = 𝑐 ( 𝑢 , 𝑣 ) − 𝑓 ( 𝑢 , 𝑣 ) = 0 c f ( u , v ) = c ( u , v ) − f ( u , v ) = 0 𝑐 ( 𝑢 , 𝑣 ) = 𝑓 ( 𝑢 , 𝑣 ) c ( u , v ) = f ( u , v ) { ( 𝑢 , 𝑣 ) ∣ 𝑢 ∈ 𝑆 , 𝑣 ∈ 𝑇 } { ( u , v ) ∣ u ∈ S , v ∈ T } ( 𝑣 , 𝑢 ) ∈ 𝐸 ( v , u ) ∈ E 𝑐 𝑓 ( 𝑢 , 𝑣 ) = 𝑐 ( 𝑢 , 𝑣 ) − 𝑓 ( 𝑢 , 𝑣 ) = 0 − 𝑓 ( 𝑢 , 𝑣 ) = 𝑓 ( 𝑣 , 𝑢 ) = 0 c f ( u , v ) = c ( u , v ) − f ( u , v ) = 0 − f ( u , v ) = f ( v , u ) = 0 { ( 𝑣 , 𝑢 ) ∣ 𝑢 ∈ 𝑆 , 𝑣 ∈ 𝑇 } { ( v , u ) ∣ u ∈ S , v ∈ T } 因此,增广停止后,上述流 𝑓 f 𝑓 f 𝐺 G { 𝑆 , 𝑇 } { S , T } 𝐺 G
容易看出,Kőnig 定理是最大流最小割定理的特殊情形.实际上,它们都和线性规划中的对偶有关.
时间复杂度分析 在整数流量的网络 𝐺 = ( 𝑉 , 𝐸 ) G = ( V , E ) 𝑂 ( | 𝐸 | | 𝑓 | ) O ( | E | | f | ) 𝑓 f 𝐺 G 𝑂 ( | 𝐸 | ) O ( | E | ) | 𝑓 | | f |
对于 Ford–Fulkerson 增广的不同实现,时间复杂度也各不相同.其中较主流的实现有 Edmonds–Karp, Dinic, SAP, ISAP 等算法,我们将在下文中分别介绍.
Edmonds–Karp 算法 算法思想 如何在 𝐺 𝑓 G f
以上算法即 Edmonds–Karp 算法.
时间复杂度分析 接下来让我们尝试分析 Edmonds–Karp 算法的时间复杂度.
显然,单轮 BFS 增广的时间复杂度是 𝑂 ( | 𝐸 | ) O ( | E | )
增广总轮数的上界是 𝑂 ( | 𝑉 | | 𝐸 | ) O ( | V | | E | )
增广总轮数的上界的证明 首先,我们引入一个引理——最短路非递减引理.具体地,我们记 𝑑 𝑓 ( 𝑢 ) d f ( u ) 𝐺 𝑓 G f 𝑢 u 𝑠 s 𝑓 f 𝑓 ′ f ′ 𝑢 u 𝑑 𝑓 ′ ( 𝑢 ) ≥ 𝑑 𝑓 ( 𝑢 ) d f ′ ( u ) ≥ d f ( u )
不妨称增广路上剩余容量最小的边是饱和边(存在多条边同时最小则取任一).如果一条有向边 ( 𝑢 , 𝑣 ) ( u , v ) ( 𝑢 , 𝑣 ) ∉ 𝐸 𝑓 ′ ( u , v ) ∉ E f ′ ( 𝑣 , 𝑢 ) ∈ 𝐸 𝑓 ′ ( v , u ) ∈ E f ′ ( 𝑢 , 𝑣 ) ( u , v )
在 𝐺 𝑓 G f ( 𝑢 , 𝑣 ) ( u , v ) 𝑑 𝑓 ( 𝑢 ) + 1 = 𝑑 𝑓 ( 𝑣 ) d f ( u ) + 1 = d f ( v ) 𝐺 𝑓 ′ G f ′ 𝐺 𝑓 ′ G f ′ ( 𝑣 , 𝑢 ) ( v , u ) 𝑑 𝑓 ′ ( 𝑣 ) + 1 = 𝑑 𝑓 ′ ( 𝑢 ) d f ′ ( v ) + 1 = d f ′ ( u ) 𝑑 𝑓 ′ ( 𝑣 ) ≥ 𝑑 𝑓 ( 𝑣 ) d f ′ ( v ) ≥ d f ( v ) 𝑑 𝑓 ′ ( 𝑢 ) ≥ 𝑑 𝑓 ( 𝑢 ) + 2 d f ′ ( u ) ≥ d f ( u ) + 2 ( 𝑢 , 𝑣 ) ( u , v ) 𝑢 u 𝑠 s 2 2
𝑠 s | 𝑉 | | V | 𝑂 ( | 𝑉 | ) O ( | V | ) 𝑂 ( | 𝑉 | | 𝐸 | ) O ( | V | | E | )
接下来我们证明最短路非递减引理,即 𝑑 𝑓 ′ ( 𝑢 ) ≥ 𝑑 𝑓 ( 𝑢 ) d f ′ ( u ) ≥ d f ( u )
最短路非递减引理的证明 考虑反证.对于某一轮增广,我们假设存在若干结点,它们在该轮增广后到 𝑠 s 𝑣 v 𝑠 s 𝑣 = a r g m i n 𝑥 ∈ 𝑉 , 𝑑 𝑓 ′ ( 𝑥 ) < 𝑑 𝑓 ( 𝑥 ) 𝑑 𝑓 ′ ( 𝑥 ) v = arg min x ∈ V , d f ′ ( x ) < d f ( x ) d f ′ ( x ) 𝑑 𝑓 ′ ( 𝑣 ) < 𝑑 𝑓 ( 𝑣 ) d f ′ ( v ) < d f ( v )
在 𝐺 𝑓 ′ G f ′ 𝑠 s 𝑣 v 𝑢 u 𝑣 v 𝑑 𝑓 ′ ( 𝑢 ) + 1 = 𝑑 𝑓 ′ ( 𝑣 ) d f ′ ( u ) + 1 = d f ′ ( v )
为了不让 𝑢 u 𝑣 v 𝑢 u 𝑑 𝑓 ′ ( 𝑢 ) ≥ 𝑑 𝑓 ( 𝑢 ) d f ′ ( u ) ≥ d f ( u )
对于上式,我们令不等号两侧同加,得 𝑑 𝑓 ′ ( 𝑣 ) ≥ 𝑑 𝑓 ( 𝑢 ) + 1 d f ′ ( v ) ≥ d f ( u ) + 1 𝑑 𝑓 ( 𝑣 ) > 𝑑 𝑓 ( 𝑢 ) + 1 d f ( v ) > d f ( u ) + 1
以下我们尝试讨论 ( 𝑢 , 𝑣 ) ( u , v )
假设有向边 ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 ( u , v ) ∈ E f 𝑑 𝑓 ( 𝑢 ) + 1 ≥ 𝑑 𝑓 ( 𝑣 ) d f ( u ) + 1 ≥ d f ( v ) 假设有向边 ( 𝑢 , 𝑣 ) ∉ 𝐸 𝑓 ( u , v ) ∉ E f 𝑢 u ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 ′ ( u , v ) ∈ E f ′ ( 𝑣 , 𝑢 ) ( v , u ) 𝑑 𝑓 ( 𝑣 ) + 1 = 𝑑 𝑓 ( 𝑢 ) d f ( v ) + 1 = d f ( u ) 由于 ( 𝑢 , 𝑣 ) ( u , v )
将单轮 BFS 增广的复杂度与增广轮数的上界相乘,我们得到 Edmonds–Karp 算法的时间复杂度是 𝑂 ( | 𝑉 | | 𝐸 | 2 ) O ( | V | | E | 2 )
代码实现 Edmonds–Karp 算法的可能实现如下.
参考代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62 constexpr int MAXN = 250 ;
constexpr int INF = 0x3f3f3f3f ;
struct Edge {
int from , to , cap , flow ;
Edge ( int u , int v , int c , int f ) : from ( u ), to ( v ), cap ( c ), flow ( f ) {}
};
struct EK {
int n , m ; // n:点数,m:边数
vector < Edge > edges ; // edges:所有边的集合
vector < int > G [ MAXN ]; // G:点 x -> x 的所有边在 edges 中的下标
int a [ MAXN ], p [ MAXN ]; // a:点 x -> BFS 过程中最近接近点 x 的边给它的最大流
// p:点 x -> BFS 过程中最近接近点 x 的边
void init ( int n ) {
for ( int i = 0 ; i < n ; i ++ ) G [ i ]. clear ();
edges . clear ();
}
void AddEdge ( int from , int to , int cap ) {
edges . push_back ( Edge ( from , to , cap , 0 ));
edges . push_back ( Edge ( to , from , 0 , 0 ));
m = edges . size ();
G [ from ]. push_back ( m - 2 );
G [ to ]. push_back ( m - 1 );
}
int Maxflow ( int s , int t ) {
int flow = 0 ;
for (;;) {
memset ( a , 0 , sizeof ( a ));
queue < int > Q ;
Q . push ( s );
a [ s ] = INF ;
while ( ! Q . empty ()) {
int x = Q . front ();
Q . pop ();
for ( int i = 0 ; i < G [ x ]. size (); i ++ ) { // 遍历以 x 作为起点的边
Edge & e = edges [ G [ x ][ i ]];
if ( ! a [ e . to ] && e . cap > e . flow ) {
p [ e . to ] = G [ x ][ i ]; // G[x][i] 是最近接近点 e.to 的边
a [ e . to ] =
min ( a [ x ], e . cap - e . flow ); // 最近接近点 e.to 的边赋给它的流
Q . push ( e . to );
}
}
if ( a [ t ]) break ; // 如果汇点接受到了流,就退出 BFS
}
if ( ! a [ t ])
break ; // 如果汇点没有接受到流,说明源点和汇点不在同一个连通分量上
for ( int u = t ; u != s ;
u = edges [ p [ u ]]. from ) { // 通过 u 追寻 BFS 过程中 s -> t 的路径
edges [ p [ u ]]. flow += a [ t ]; // 增加路径上边的 flow 值
edges [ p [ u ] ^ 1 ]. flow -= a [ t ]; // 减小反向路径的 flow 值
}
flow += a [ t ];
}
return flow ;
}
};
Dinic 算法 算法思想 考虑在增广前先对 𝐺 𝑓 G f 𝑢 u 𝑠 s 𝑑 ( 𝑢 ) d ( u ) 𝑢 u 𝑣 v 𝑢 u 𝐺 𝑓 G f 𝐺 𝐿 = ( 𝑉 , 𝐸 𝐿 ) G L = ( V , E L ) 𝐺 𝑓 = ( 𝑉 , 𝐸 𝑓 ) G f = ( V , E f ) 𝐸 𝐿 = { ( 𝑢 , 𝑣 ) ∣ ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 , 𝑑 ( 𝑢 ) + 1 = 𝑑 ( 𝑣 ) } E L = { ( u , v ) ∣ ( u , v ) ∈ E f , d ( u ) + 1 = d ( v ) }
如果我们在层次图 𝐺 𝐿 G L 𝑓 𝑏 f b 𝐺 𝐿 G L 𝑓 𝑏 f b 𝑓 𝑏 f b 𝐺 𝐿 G L
Warning 尽管在上文中我们仅在单条增广路上定义了增广/增广流,广义地,「增广」一词不仅可以用于单条路径上的增广流,也可以用于若干增广流的并——后者才是我们定义阻塞流时使用的意义.
定义层次图和阻塞流后,Dinic 算法的流程如下.
在 𝐺 𝑓 G f 𝐺 𝐿 G L 在 𝐺 𝐿 G L 𝑓 𝑏 f b 将 𝑓 𝑏 f b 𝑓 f 𝑓 ← 𝑓 + 𝑓 𝑏 f ← f + f b 重复以上过程直到不存在从 𝑠 s 𝑡 t 此时的 𝑓 f
在分析这一算法的复杂度之前,我们需要特别说明「在 𝐺 𝐿 G L 𝑓 𝑏 f b
注意到在 𝐺 𝐿 G L 𝑢 u 𝑢 u 𝑢 u 𝑂 ( | 𝐸 | 2 ) O ( | E | 2 ) ( 𝑢 , 𝑣 ) ( u , v ) ( 𝑢 , 𝑣 ) ( u , v ) 𝑣 v 𝑢 u ( 𝑢 , 𝑣 ) ( u , v ) 𝑢 u 𝑢 u
多路增广 多路增广是 Dinic 算法的一个常数优化——如果我们在层次图上找到了一条从 𝑠 s 𝑡 t 𝑝 p 𝑠 s 𝑝 p
常见误区 可能是由于大量网络资料的错误表述引发以讹传讹的情形,相当数量的选手喜欢将当前弧优化和多路增广并列称为 Dinic 算法的两种优化.实际上,当前弧优化是用于保证 Dinic 时间复杂度正确性的一部分,而多路增广只是一个不影响复杂度的常数优化.
时间复杂度分析 应用当前弧优化后,对 Dinic 算法的时间复杂度分析如下.
首先,我们尝试证明单轮增广中 DFS 求阻塞流的时间复杂度是 𝑂 ( | 𝑉 | | 𝐸 | ) O ( | V | | E | )
单轮增广的时间复杂度的证明 考虑阻塞流 𝑓 𝑏 f b 𝐺 𝐿 G L | 𝑉 | | V |
每找到一条增广路就有一条饱和边消失(剩余容量清零).考虑阻塞流 𝑓 𝑏 f b 𝐸 1 E 1 𝐺 𝐿 G L 𝐸 1 E 1 𝐸 𝐿 E L
此外,对于沿当前弧跳转但由于某个位置阻塞所以没有成功得到增广路的情形,我们将这些不完整的路径上的最后一条边形成的边集记作 𝐸 2 E 2 𝐸 2 E 2 𝐸 1 E 1 𝐸 2 E 2 𝐸 1 ∪ 𝐸 2 E 1 ∪ E 2 𝐸 𝐿 E L
由于 𝐸 1 ∪ 𝐸 2 E 1 ∪ E 2 | 𝑉 | | V | | 𝑉 | | 𝐸 𝐿 | | V | | E L |
常见伪证一则 对于每个结点,我们维护下一条可以增广的边,而当前弧最多变化 | 𝐸 | | E | 𝑂 ( | 𝑉 | | 𝐸 | ) O ( | V | | E | )
Bug 「当前弧最多变化 | 𝐸 | | E | | 𝐸 | | E | 𝑢 u
注意到层次图的层数显然不可能超过 | 𝑉 | | V | 𝑂 ( | 𝑉 | ) O ( | V | )
层次图层数单调性的证明 我们需要引入预流推进类算法(另一类最大流算法)中的一个概念——高度标号.为了更方便地结合高度标号表述我们的证明,在证明过程中,我们令 𝑑 𝑓 ( 𝑢 ) d f ( u ) 𝐺 𝑓 G f 𝑢 u 汇点 𝑡 t 汇点 而非源点出发进行分层(这并没有本质上的区别).对于某一轮增广,我们用 𝑓 f 𝑓 ′ f ′ 𝐺 𝐿 = ( 𝑉 , 𝐸 𝐿 ) G L = ( V , E L ) 𝐺 ′ 𝐿 = ( 𝑉 , 𝐸 ′ 𝐿 ) G L ′ = ( V , E L ′ )
我们给高度标号一个不严格的临时定义——在网络 𝐺 = ( 𝑉 , 𝐸 ) G = ( V , E ) ℎ h 𝑉 V 𝑁 N ℎ h 𝐺 G ℎ ( 𝑢 ) ≤ ℎ ( 𝑣 ) + 1 h ( u ) ≤ h ( v ) + 1 ( 𝑢 , 𝑣 ) ∈ 𝐸 ( u , v ) ∈ E
考察所有 𝐸 𝑓 ′ E f ′ ( 𝑢 , 𝑣 ) ( u , v ) ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 ′ ( u , v ) ∈ E f ′
( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 ( u , v ) ∈ E f 𝑑 𝑓 ( 𝑢 ) ≤ 𝑑 𝑓 ( 𝑣 ) + 1 d f ( u ) ≤ d f ( v ) + 1 ( 𝑢 , 𝑣 ) ∉ 𝐸 𝑓 ( u , v ) ∉ E f ( 𝑣 , 𝑢 ) ( v , u ) 𝑑 𝑓 ( 𝑢 ) + 1 = 𝑑 𝑓 ( 𝑣 ) d f ( u ) + 1 = d f ( v ) 以上观察让我们得出一个结论——𝑑 𝑓 d f 𝐺 𝑓 ′ G f ′ 𝐺 𝑓 ′ G f ′ 𝐺 ′ 𝐿 G L ′
现在,对于一条 𝐺 ′ 𝐿 G L ′ 𝑝 = ( 𝑠 , … , 𝑢 , 𝑣 , … , 𝑡 ) p = ( s , … , u , v , … , t ) 𝑝 p 𝑡 t 𝑠 s 𝑣 v 𝑢 u 𝑢 u 𝑑 𝑓 ′ ( 𝑢 ) d f ′ ( u ) 𝑑 𝑓 ′ ( 𝑣 ) d f ′ ( v ) 1 1 𝑑 𝑓 d f 𝐺 ′ 𝐿 G L ′ 𝑑 𝑓 ( 𝑢 ) d f ( u ) 𝑑 𝑓 ( 𝑣 ) d f ( v ) 1 1 𝑑 𝑓 ′ ( 𝑠 ) ≥ 𝑑 𝑓 ( 𝑠 ) d f ′ ( s ) ≥ d f ( s ) 𝑑 𝑓 ( 𝑢 ) = 𝑑 𝑓 ( 𝑣 ) + 1 d f ( u ) = d f ( v ) + 1 ( 𝑢 , 𝑣 ) ∈ 𝑝 ( u , v ) ∈ p 𝑑 𝑓 ′ ( 𝑠 ) > 𝑑 𝑓 ( 𝑠 ) d f ′ ( s ) > d f ( s )
考虑反证,我们假设 𝑑 𝑓 ′ ( 𝑠 ) = 𝑑 𝑓 ( 𝑠 ) d f ′ ( s ) = d f ( s ) 𝐺 ′ 𝐿 G L ′ 𝑝 p ( 𝑢 , 𝑣 ) ( u , v ) ( 𝑢 , 𝑣 ) ( u , v ) 𝐺 𝐿 G L 𝑑 𝑓 ( 𝑠 ) = 𝑑 𝑓 ′ ( 𝑠 ) d f ( s ) = d f ′ ( s ) 𝐺 𝐿 G L
令 ( 𝑢 , 𝑣 ) ( u , v )
( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 ( u , v ) ∈ E f 𝑑 𝑓 ( 𝑢 ) ≤ 𝑑 𝑓 ( 𝑣 ) + 1 d f ( u ) ≤ d f ( v ) + 1 ( 𝑢 , 𝑣 ) ∉ 𝐸 𝐿 ( u , v ) ∉ E L 𝐸 ′ 𝐿 E L ′ ( 𝑢 , 𝑣 ) ∉ 𝐸 𝑓 ( u , v ) ∉ E f ( 𝑢 , 𝑣 ) ( u , v ) ( 𝑣 , 𝑢 ) ( v , u ) 𝑑 𝑓 ( 𝑢 ) = 𝑑 𝑓 ( 𝑣 ) − 1 d f ( u ) = d f ( v ) − 1 由于我们无论以何种方式满足断言均得到 𝑑 𝑓 ( 𝑢 ) ≠ 𝑑 𝑓 ( 𝑣 ) + 1 d f ( u ) ≠ d f ( v ) + 1 𝑑 𝑓 ′ ( 𝑠 ) ≥ 𝑑 𝑓 ( 𝑠 ) d f ′ ( s ) ≥ d f ( s ) 𝑑 𝑓 ′ ( 𝑠 ) = 𝑑 𝑓 ( 𝑠 ) d f ′ ( s ) = d f ( s )
常见伪证另一则 考虑反证.假设层次图的层数在一轮增广结束后较原先相等,则层次图上应仍存在至少一条从 𝑠 s 𝑡 t 1 1
Bug 「一轮增广结束后新的层次图上 𝑠 s 𝑡 t 𝑠 s 𝑡 t
将单轮增广的时间复杂度 𝑂 ( | 𝑉 | | 𝐸 | ) O ( | V | | E | ) 𝑂 ( | 𝑉 | ) O ( | V | ) 𝑂 ( | 𝑉 | 2 | 𝐸 | ) O ( | V | 2 | E | )
如果需要令 Dinic 算法的实际运行时间接近其理论上界,我们需要构造有特殊性质的网络作为输入.由于在算法竞赛实践中,对于网络流知识相关的考察常侧重于将原问题建模为网络流问题的技巧.此时,我们的建模通常不包含令 Dinic 算法执行缓慢的特殊性质;恰恰相反,Dinic 算法在大部分图上效率非常优秀.因此,网络流问题的数据范围通常较大,「将 | 𝑉 | , | 𝐸 | | V | , | E | | 𝑉 | 2 | 𝐸 | | V | 2 | E |
特殊情形下的时间复杂度分析 在一些性质良好的图上,Dinic 算法有更好的时间复杂度.
对于网络 𝐺 = ( 𝑉 , 𝐸 ) G = ( V , E ) 1 1 𝑐 ( 𝑢 , 𝑣 ) ∈ { 0 , 1 } c ( u , v ) ∈ { 0 , 1 } ( 𝑢 , 𝑣 ) ∈ 𝐸 ( u , v ) ∈ E 𝐺 G
在单位容量的网络中,Dinic 算法的单轮增广的时间复杂度为 𝑂 ( | 𝐸 | ) O ( | E | )
证明 这是因为,每次增广都会导致增广路上的所有边均饱和并消失,故单轮增广中每条边只能被增广一次.
在单位容量的网络中,Dinic 算法的增广轮数是 𝑂 ( | 𝐸 | 1 2 ) O ( | E | 1 2 )
证明 以源点 𝑠 s 𝑑 𝑓 ( 𝑢 ) d f ( u ) 𝐺 𝑓 G f 𝑢 u 𝑠 s { 𝑢 ∣ 𝑢 ∈ 𝑉 , 𝑑 𝑓 ( 𝑢 ) = 𝑘 } { u ∣ u ∈ V , d f ( u ) = k } 𝑘 k 𝐷 𝑘 D k 𝑆 𝑘 = ∪ 𝑖 ≤ 𝑘 𝐷 𝑖 S k = ∪ i ≤ k D i
假设我们已经进行了 | 𝐸 | 1 2 | E | 1 2 𝑘 k { ( 𝑢 , 𝑣 ) ∣ 𝑢 ∈ 𝐷 𝑘 , 𝑣 ∈ 𝐷 𝑘 + 1 , ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 } { ( u , v ) ∣ u ∈ D k , v ∈ D k + 1 , ( u , v ) ∈ E f } | 𝐸 | | 𝐸 | 1 2 ≈ | 𝐸 | 1 2 | E | | E | 1 2 ≈ | E | 1 2 { 𝑆 𝑘 , 𝑉 − 𝑆 𝑘 } { S k , V − S k } 𝐺 𝑓 G f 𝑠 s 𝑡 t | 𝐸 | 1 2 | E | 1 2 𝐺 𝑓 G f | 𝐸 | 1 2 | E | 1 2 𝐺 𝑓 G f | 𝐸 | 1 2 | E | 1 2 𝑂 ( | 𝐸 | 1 2 ) O ( | E | 1 2 )
在单位容量的网络中,Dinic 算法的增广轮数是 𝑂 ( | 𝑉 | 2 3 ) O ( | V | 2 3 )
证明 假设我们已经进行了 2 | 𝑉 | 2 3 2 | V | 2 3 | 𝑉 | 2 3 | V | 2 3 | 𝑉 | 1 3 | V | 1 3 𝑘 k | 𝑉 | 1 3 | V | 1 3 | 𝐷 𝑘 | ≤ | 𝑉 | 1 3 | D k | ≤ | V | 1 3 | 𝐷 𝑘 + 1 | ≤ | 𝑉 | 1 3 | D k + 1 | ≤ | V | 1 3
为最大化 𝐷 𝑘 D k 𝐷 𝑘 + 1 D k + 1 { ( 𝑢 , 𝑣 ) ∣ 𝑢 ∈ 𝐷 𝑘 , 𝑣 ∈ 𝐷 𝑘 + 1 , ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 } { ( u , v ) ∣ u ∈ D k , v ∈ D k + 1 , ( u , v ) ∈ E f } | 𝑉 | 2 3 | V | 2 3 { 𝑆 𝑘 , 𝑉 − 𝑆 𝑘 } { S k , V − S k } 𝐺 𝑓 G f 𝑠 s 𝑡 t | 𝑉 | 2 3 | V | 2 3 𝐺 𝑓 G f | 𝑉 | 2 3 | V | 2 3 𝐺 𝑓 G f | 𝑉 | 2 3 | V | 2 3 𝑂 ( | 𝑉 | 2 3 ) O ( | V | 2 3 )
在单位容量的网络中,如果除源汇点外每个结点 𝑢 u d e g i n ( 𝑢 ) = 1 deg in ( u ) = 1 d e g o u t ( 𝑢 ) = 1 deg out ( u ) = 1 𝑂 ( | 𝑉 | 1 2 ) O ( | V | 1 2 ) d e g i n ( 𝑢 ) deg in ( u ) d e g o u t ( 𝑢 ) deg out ( u ) 𝑢 u
证明 我们引入以下引理——对于这一形式的网络,其上的任意流总是可以分解成若干条单位流量的、点不交 的增广路.
假设我们已经进行了 | 𝑉 | 1 2 | V | 1 2 | 𝑉 | 1 2 | V | 1 2
考虑 𝐺 𝑓 G f | 𝑉 | | 𝑉 | 1 2 ≈ | 𝑉 | 1 2 | V | | V | 1 2 ≈ | V | 1 2 𝐺 𝑓 G f | 𝑉 | 1 2 | V | 1 2 𝑂 ( | 𝑉 | 1 2 ) O ( | V | 1 2 )
综上,我们得出一些推论.
在单位容量的网络上,Dinic 算法的总时间复杂度是 𝑂 ( | 𝐸 | m i n ( | 𝐸 | 1 2 , | 𝑉 | 2 3 ) ) O ( | E | min ( | E | 1 2 , | V | 2 3 ) ) 在单位容量的网络上,如果除源汇点外每个结点 𝑢 u d e g i n ( 𝑢 ) = 1 deg in ( u ) = 1 d e g o u t ( 𝑢 ) = 1 deg out ( u ) = 1 𝑂 ( | 𝐸 | | 𝑉 | 1 2 ) O ( | E | | V | 1 2 ) 代码实现 参考代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67 struct MF {
struct edge {
int v , nxt , cap , flow ;
} e [ N ];
int fir [ N ], cnt = 0 ;
int n , S , T ;
ll maxflow = 0 ;
int dep [ N ], cur [ N ];
void init () {
memset ( fir , -1 , sizeof fir );
cnt = 0 ;
}
void addedge ( int u , int v , int w ) {
e [ cnt ] = { v , fir [ u ], w , 0 };
fir [ u ] = cnt ++ ;
e [ cnt ] = { u , fir [ v ], 0 , 0 };
fir [ v ] = cnt ++ ;
}
bool bfs () {
queue < int > q ;
memset ( dep , 0 , sizeof ( int ) * ( n + 1 ));
dep [ S ] = 1 ;
q . push ( S );
while ( q . size ()) {
int u = q . front ();
q . pop ();
for ( int i = fir [ u ]; ~ i ; i = e [ i ]. nxt ) {
int v = e [ i ]. v ;
if (( ! dep [ v ]) && ( e [ i ]. cap > e [ i ]. flow )) {
dep [ v ] = dep [ u ] + 1 ;
q . push ( v );
}
}
}
return dep [ T ];
}
int dfs ( int u , int flow ) {
if (( u == T ) || ( ! flow )) return flow ;
int ret = 0 ;
for ( int & i = cur [ u ]; ~ i ; i = e [ i ]. nxt ) {
int v = e [ i ]. v , d ;
if (( dep [ v ] == dep [ u ] + 1 ) &&
( d = dfs ( v , min ( flow - ret , e [ i ]. cap - e [ i ]. flow )))) {
ret += d ;
e [ i ]. flow += d ;
e [ i ^ 1 ]. flow -= d ;
if ( ret == flow ) return ret ;
}
}
return ret ;
}
void dinic () {
while ( bfs ()) {
memcpy ( cur , fir , sizeof ( int ) * ( n + 1 ));
maxflow += dfs ( S , INF );
}
}
} mf ;
MPM 算法 MPM (Malhotra, Pramodh-Kumar and Maheshwari) 算法得到最大流的方式有两种:使用基于堆的优先队列,时间复杂度为 𝑂 ( 𝑛 3 l o g 𝑛 ) O ( n 3 log n ) 𝑂 ( 𝑛 3 ) O ( n 3 ) 𝑂 ( 𝑛 3 ) O ( n 3 )
MPM 算法的整体结构和 Dinic 算法类似,也是分阶段运行的.在每个阶段,在 𝐺 G 𝑂 ( 𝑛 2 ) O ( n 2 )
MPM 算法需要考虑顶点而不是边的容量.在分层网络 𝐿 L 𝑣 v 𝑝 ( 𝑣 ) p ( v )
𝑝 𝑖 𝑛 ( 𝑣 ) = ∑ ( 𝑢 , 𝑣 ) ∈ 𝐿 ( 𝑐 ( 𝑢 , 𝑣 ) − 𝑓 ( 𝑢 , 𝑣 ) ) 𝑝 𝑜 𝑢 𝑡 ( 𝑣 ) = ∑ ( 𝑣 , 𝑢 ) ∈ 𝐿 ( 𝑐 ( 𝑣 , 𝑢 ) − 𝑓 ( 𝑣 , 𝑢 ) ) 𝑝 ( 𝑣 ) = m i n ( 𝑝 𝑖 𝑛 ( 𝑣 ) , 𝑝 𝑜 𝑢 𝑡 ( 𝑣 ) ) p i n ( v ) = ∑ ( u , v ) ∈ L ( c ( u , v ) − f ( u , v ) ) p o u t ( v ) = ∑ ( v , u ) ∈ L ( c ( v , u ) − f ( v , u ) ) p ( v ) = min ( p i n ( v ) , p o u t ( v ) ) 我们称节点 𝑟 r 𝑝 ( 𝑟 ) = m i n 𝑝 ( 𝑣 ) p ( r ) = min p ( v ) 𝑟 r 𝑟 r 𝑝 ( 𝑟 ) p ( r ) 0 0 𝐿 L 𝐿 L 𝑝 ( 𝑟 ) p ( r ) 𝑠 s 𝑟 r 𝑡 t 𝑝 ( 𝑟 ) p ( r ) 𝐿 L 𝑠 s 𝑡 t
时间复杂度分析 MPM 算法的每个阶段都需要 𝑂 ( 𝑉 2 ) O ( V 2 ) 𝑉 V 𝑉 V 𝑂 ( 𝑉 2 + 𝐸 ) = 𝑂 ( 𝑉 2 ) O ( V 2 + E ) = O ( V 2 ) 𝑉 V 𝑂 ( 𝑉 3 ) O ( V 3 )
阶段总数小于 V 的证明 MPM 算法在少于 𝑉 V
引理 1 :每次迭代后,从 𝑠 s 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑣 ] ≥ 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑣 ] l e v e l i + 1 [ v ] ≥ l e v e l i [ v ]
证明 :固定一个阶段 𝑖 i 𝑣 v 𝐺 𝑅 𝑖 G i R 𝑠 s 𝑣 v 𝑃 P 𝑃 P 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑣 ] l e v e l i [ v ] 𝐺 𝑅 𝑖 G i R 𝐺 𝑅 𝑖 G i R 𝑃 P 𝐺 𝑅 𝑖 G i R 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑣 ] ≥ 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑣 ] l e v e l i + 1 [ v ] ≥ l e v e l i [ v ] 𝑃 P 𝐺 𝑅 𝑖 G i R 𝑃 P ( 𝑢 , 𝑤 ) ( u , w ) 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑢 ] ≥ 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑢 ] l e v e l i + 1 [ u ] ≥ l e v e l i [ u ] ( 𝑢 , 𝑤 ) ( u , w ) 𝐺 𝑅 𝑖 G i R ( 𝑢 , 𝑤 ) ( u , w ) 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑢 ] = 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑤 ] + 1 l e v e l i [ u ] = l e v e l i [ w ] + 1 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑤 ] = 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑢 ] + 1 l e v e l i + 1 [ w ] = l e v e l i + 1 [ u ] + 1 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑢 ] ≥ 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑢 ] l e v e l i + 1 [ u ] ≥ l e v e l i [ u ] 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑤 ] ≥ 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑤 ] + 2 l e v e l i + 1 [ w ] ≥ l e v e l i [ w ] + 2
引理 2 :𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑡 ] > 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑡 ] l e v e l i + 1 [ t ] > l e v e l i [ t ]
证明 :从引理一我们得出,𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑡 ] ≥ 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑡 ] l e v e l i + 1 [ t ] ≥ l e v e l i [ t ] 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 + 1 [ 𝑡 ] = 𝑙 𝑒 𝑣 𝑒 𝑙 𝑖 [ 𝑡 ] l e v e l i + 1 [ t ] = l e v e l i [ t ] 𝐺 𝑅 𝑖 G i R 𝐺 𝑅 𝑖 G i R 𝐺 𝑅 𝑖 G i R
实现 参考代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179 struct MPM {
struct FlowEdge {
int v , u ;
long long cap , flow ;
FlowEdge () {}
FlowEdge ( int _v , int _u , long long _cap , long long _flow )
: v ( _v ), u ( _u ), cap ( _cap ), flow ( _flow ) {}
FlowEdge ( int _v , int _u , long long _cap )
: v ( _v ), u ( _u ), cap ( _cap ), flow ( 0l l ) {}
};
constexpr static long long flow_inf = 1e18 ;
vector < FlowEdge > edges ;
vector < char > alive ;
vector < long long > pin , pout ;
vector < list < int >> in , out ;
vector < vector < int >> adj ;
vector < long long > ex ;
int n , m = 0 ;
int s , t ;
vector < int > level ;
vector < int > q ;
int qh , qt ;
void resize ( int _n ) {
n = _n ;
ex . resize ( n );
q . resize ( n );
pin . resize ( n );
pout . resize ( n );
adj . resize ( n );
level . resize ( n );
in . resize ( n );
out . resize ( n );
}
MPM () {}
MPM ( int _n , int _s , int _t ) {
resize ( _n );
s = _s ;
t = _t ;
}
void add_edge ( int v , int u , long long cap ) {
edges . push_back ( FlowEdge ( v , u , cap ));
edges . push_back ( FlowEdge ( u , v , 0 ));
adj [ v ]. push_back ( m );
adj [ u ]. push_back ( m + 1 );
m += 2 ;
}
bool bfs () {
while ( qh < qt ) {
int v = q [ qh ++ ];
for ( int id : adj [ v ]) {
if ( edges [ id ]. cap - edges [ id ]. flow < 1 ) continue ;
if ( level [ edges [ id ]. u ] != -1 ) continue ;
level [ edges [ id ]. u ] = level [ v ] + 1 ;
q [ qt ++ ] = edges [ id ]. u ;
}
}
return level [ t ] != -1 ;
}
long long pot ( int v ) { return min ( pin [ v ], pout [ v ]); }
void remove_node ( int v ) {
for ( int i : in [ v ]) {
int u = edges [ i ]. v ;
auto it = find ( out [ u ]. begin (), out [ u ]. end (), i );
out [ u ]. erase ( it );
pout [ u ] -= edges [ i ]. cap - edges [ i ]. flow ;
}
for ( int i : out [ v ]) {
int u = edges [ i ]. u ;
auto it = find ( in [ u ]. begin (), in [ u ]. end (), i );
in [ u ]. erase ( it );
pin [ u ] -= edges [ i ]. cap - edges [ i ]. flow ;
}
}
void push ( int from , int to , long long f , bool forw ) {
qh = qt = 0 ;
ex . assign ( n , 0 );
ex [ from ] = f ;
q [ qt ++ ] = from ;
while ( qh < qt ) {
int v = q [ qh ++ ];
if ( v == to ) break ;
long long must = ex [ v ];
auto it = forw ? out [ v ]. begin () : in [ v ]. begin ();
while ( true ) {
int u = forw ? edges [ * it ]. u : edges [ * it ]. v ;
long long pushed = min ( must , edges [ * it ]. cap - edges [ * it ]. flow );
if ( pushed == 0 ) break ;
if ( forw ) {
pout [ v ] -= pushed ;
pin [ u ] -= pushed ;
} else {
pin [ v ] -= pushed ;
pout [ u ] -= pushed ;
}
if ( ex [ u ] == 0 ) q [ qt ++ ] = u ;
ex [ u ] += pushed ;
edges [ * it ]. flow += pushed ;
edges [( * it ) ^ 1 ]. flow -= pushed ;
must -= pushed ;
if ( edges [ * it ]. cap - edges [ * it ]. flow == 0 ) {
auto jt = it ;
++ jt ;
if ( forw ) {
in [ u ]. erase ( find ( in [ u ]. begin (), in [ u ]. end (), * it ));
out [ v ]. erase ( it );
} else {
out [ u ]. erase ( find ( out [ u ]. begin (), out [ u ]. end (), * it ));
in [ v ]. erase ( it );
}
it = jt ;
} else
break ;
if ( ! must ) break ;
}
}
}
long long flow () {
long long ans = 0 ;
while ( true ) {
pin . assign ( n , 0 );
pout . assign ( n , 0 );
level . assign ( n , -1 );
alive . assign ( n , true );
level [ s ] = 0 ;
qh = 0 ;
qt = 1 ;
q [ 0 ] = s ;
if ( ! bfs ()) break ;
for ( int i = 0 ; i < n ; i ++ ) {
out [ i ]. clear ();
in [ i ]. clear ();
}
for ( int i = 0 ; i < m ; i ++ ) {
if ( edges [ i ]. cap - edges [ i ]. flow == 0 ) continue ;
int v = edges [ i ]. v , u = edges [ i ]. u ;
if ( level [ v ] + 1 == level [ u ] && ( level [ u ] < level [ t ] || u == t )) {
in [ u ]. push_back ( i );
out [ v ]. push_back ( i );
pin [ u ] += edges [ i ]. cap - edges [ i ]. flow ;
pout [ v ] += edges [ i ]. cap - edges [ i ]. flow ;
}
}
pin [ s ] = pout [ t ] = flow_inf ;
while ( true ) {
int v = -1 ;
for ( int i = 0 ; i < n ; i ++ ) {
if ( ! alive [ i ]) continue ;
if ( v == -1 || pot ( i ) < pot ( v )) v = i ;
}
if ( v == -1 ) break ;
if ( pot ( v ) == 0 ) {
alive [ v ] = false ;
remove_node ( v );
continue ;
}
long long f = pot ( v );
ans += f ;
push ( v , s , f , false );
push ( v , t , f , true );
alive [ v ] = false ;
remove_node ( v );
}
}
return ans ;
}
};
ISAP 在 Dinic 算法中,我们每次求完增广路后都要跑 BFS 来分层,有没有更高效的方法呢?
答案就是下面要介绍的 ISAP 算法.
过程 和 Dinic 算法一样,我们还是先跑 BFS 对图上的点进行分层,不过与 Dinic 略有不同的是,我们选择在反图上,从 𝑡 t 𝑠 s
执行完分层过程后,我们通过 DFS 来找增广路.
增广的过程和 Dinic 类似,我们只选择比当前点层数少 1 1
与 Dinic 不同的是,我们并不会重跑 BFS 来对图上的点重新分层,而是在增广的过程中就完成重分层过程.
具体来说,设 𝑖 i 𝑑 𝑖 d i 𝑖 i 𝑖 i 𝑗 j 𝑑 𝑖 ← 𝑑 𝑗 + 1 d i ← d j + 1 𝑖 i 𝑑 𝑖 ← 𝑛 d i ← n
容易发现,当 𝑑 𝑠 ≥ 𝑛 d s ≥ n
和 Dinic 类似,ISAP 中也存在 当前弧优化 .
而 ISAP 还存在另外一个优化,我们记录层数为 𝑖 i 𝑛 𝑢 𝑚 𝑖 n u m i 𝑥 x 𝑦 y 𝑛 𝑢 𝑚 n u m 𝑛 𝑢 𝑚 𝑥 = 0 n u m x = 0 𝑑 𝑠 d s 𝑛 n GAP 优化 .
实现 参考代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111 struct Edge {
int from , to , cap , flow ;
Edge ( int u , int v , int c , int f ) : from ( u ), to ( v ), cap ( c ), flow ( f ) {}
};
bool operator < ( const Edge & a , const Edge & b ) {
return a . from < b . from || ( a . from == b . from && a . to < b . to );
}
struct ISAP {
int n , m , s , t ;
vector < Edge > edges ;
vector < int > G [ MAXN ];
bool vis [ MAXN ];
int d [ MAXN ];
int cur [ MAXN ];
int p [ MAXN ];
int num [ MAXN ];
void AddEdge ( int from , int to , int cap ) {
edges . push_back ( Edge ( from , to , cap , 0 ));
edges . push_back ( Edge ( to , from , 0 , 0 ));
m = edges . size ();
G [ from ]. push_back ( m - 2 );
G [ to ]. push_back ( m - 1 );
}
bool BFS () {
memset ( vis , 0 , sizeof ( vis ));
queue < int > Q ;
Q . push ( t );
vis [ t ] = true ;
d [ t ] = 0 ;
while ( ! Q . empty ()) {
int x = Q . front ();
Q . pop ();
for ( int i = 0 ; i < G [ x ]. size (); i ++ ) {
Edge & e = edges [ G [ x ][ i ] ^ 1 ];
if ( ! vis [ e . from ] && e . cap > e . flow ) {
vis [ e . from ] = true ;
d [ e . from ] = d [ x ] + 1 ;
Q . push ( e . from );
}
}
}
return vis [ s ];
}
void init ( int n ) {
this -> n = n ;
for ( int i = 0 ; i < n ; i ++ ) G [ i ]. clear ();
edges . clear ();
}
int Augment () {
int x = t , a = INF ;
while ( x != s ) {
Edge & e = edges [ p [ x ]];
a = min ( a , e . cap - e . flow );
x = edges [ p [ x ]]. from ;
}
x = t ;
while ( x != s ) {
edges [ p [ x ]]. flow += a ;
edges [ p [ x ] ^ 1 ]. flow -= a ;
x = edges [ p [ x ]]. from ;
}
return a ;
}
int Maxflow ( int s , int t ) {
this -> s = s ;
this -> t = t ;
int flow = 0 ;
BFS ();
memset ( num , 0 , sizeof ( num ));
for ( int i = 0 ; i < n ; i ++ ) num [ d [ i ]] ++ ;
int x = s ;
memset ( cur , 0 , sizeof ( cur ));
while ( d [ s ] < n ) {
if ( x == t ) {
flow += Augment ();
x = s ;
}
int ok = 0 ;
for ( int i = cur [ x ]; i < G [ x ]. size (); i ++ ) {
Edge & e = edges [ G [ x ][ i ]];
if ( e . cap > e . flow && d [ x ] == d [ e . to ] + 1 ) {
ok = 1 ;
p [ e . to ] = G [ x ][ i ];
cur [ x ] = i ;
x = e . to ;
break ;
}
}
if ( ! ok ) {
int m = n - 1 ;
for ( int i = 0 ; i < G [ x ]. size (); i ++ ) {
Edge & e = edges [ G [ x ][ i ]];
if ( e . cap > e . flow ) m = min ( m , d [ e . to ]);
}
if ( -- num [ d [ x ]] == 0 ) break ;
num [ d [ x ] = m + 1 ] ++ ;
cur [ x ] = 0 ;
if ( x != s ) x = edges [ p [ x ]]. from ;
}
}
return flow ;
}
};
Push-Relabel 预流推进算法 该方法在求解过程中忽略流守恒性,并每次对一个结点更新信息,以求解最大流.
通用的预流推进算法 首先我们介绍预流推进算法的主要思想,以及一个可行的暴力实现算法.
预流推进算法通过对单个结点的更新操作,直到没有结点需要更新来求解最大流.
算法过程维护的流函数不一定保持流守恒性,对于一个结点,我们允许进入结点的流超过流出结点的流,超过的部分被称为结点 𝑢 ( 𝑢 ∈ 𝑉 − { 𝑠 , 𝑡 } ) u ( u ∈ V − { s , t } ) 超额流 𝑒 ( 𝑢 ) e ( u )
𝑒 ( 𝑢 ) = ∑ ( 𝑥 , 𝑢 ) ∈ 𝐸 𝑓 ( 𝑥 , 𝑢 ) − ∑ ( 𝑢 , 𝑦 ) ∈ 𝐸 𝑓 ( 𝑢 , 𝑦 ) e ( u ) = ∑ ( x , u ) ∈ E f ( x , u ) − ∑ ( u , y ) ∈ E f ( u , y ) 若 𝑒 ( 𝑢 ) > 0 e ( u ) > 0 𝑢 u 溢出 𝑠 s 𝑡 t
预流推进算法维护每个结点的高度 ℎ ( 𝑢 ) h ( u ) 𝑢 u 𝑢 u 𝑢 u 𝑢 u 𝑢 u
高度函数 准确地说,预流推进维护以下的一个映射 ℎ : 𝑉 → 𝐍 h : V → N
ℎ ( 𝑠 ) = | 𝑉 | , ℎ ( 𝑡 ) = 0 h ( s ) = | V | , h ( t ) = 0 ∀ ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 , ℎ ( 𝑢 ) ≤ ℎ ( 𝑣 ) + 1 ∀ ( u , v ) ∈ E f , h ( u ) ≤ h ( v ) + 1 称 ℎ h 𝐺 𝑓 = ( 𝑉 𝑓 , 𝐸 𝑓 ) G f = ( V f , E f )
引理 1:设 𝐺 𝑓 G f ℎ h 𝑢 , 𝑣 ∈ 𝑉 u , v ∈ V ℎ ( 𝑢 ) > ℎ ( 𝑣 ) + 1 h ( u ) > h ( v ) + 1 ( 𝑢 , 𝑣 ) ( u , v ) 𝐺 𝑓 G f
算法只会在 ℎ ( 𝑢 ) = ℎ ( 𝑣 ) + 1 h ( u ) = h ( v ) + 1
推送(Push) 适用条件:结点 𝑢 u 𝑣 ( ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 , 𝑐 ( 𝑢 , 𝑣 ) − 𝑓 ( 𝑢 , 𝑣 ) > 0 , ℎ ( 𝑢 ) = ℎ ( 𝑣 ) + 1 ) v ( ( u , v ) ∈ E f , c ( u , v ) − f ( u , v ) > 0 , h ( u ) = h ( v ) + 1 ) ( 𝑢 , 𝑣 ) ( u , v )
于是,我们尽可能将超额流从 𝑢 u 𝑣 v 𝑐 ( 𝑢 , 𝑣 ) − 𝑓 ( 𝑢 , 𝑣 ) c ( u , v ) − f ( u , v ) 𝑣 v
如果 ( 𝑢 , 𝑣 ) ( u , v )
重贴标签(Relabel) 适用条件:如果结点 𝑢 u ∀ ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 , ℎ ( 𝑢 ) ≤ ℎ ( 𝑣 ) ∀ ( u , v ) ∈ E f , h ( u ) ≤ h ( v ) 𝑢 u
则将 ℎ ( 𝑢 ) h ( u ) m i n ( 𝑢 , 𝑣 ) ∈ 𝐸 𝑓 ℎ ( 𝑣 ) + 1 min ( u , v ) ∈ E f h ( v ) + 1
初始化 ∀ ( 𝑢 , 𝑣 ) ∈ 𝐸 , 𝑓 ( 𝑢 , 𝑣 ) = { 𝑐 ( 𝑢 , 𝑣 ) , 𝑢 = 𝑠 0 , 𝑢 ≠ 𝑠 ∀ ( u , v ) ∈ E , f ( u , v ) = { c ( u , v ) , u = s 0 , u ≠ s ∀ 𝑢 ∈ 𝑉 , ℎ ( 𝑢 ) = { | 𝑉 | , 𝑢 = 𝑠 0 , 𝑢 ≠ 𝑠 ∀ u ∈ V , h ( u ) = { | V | , u = s 0 , u ≠ s 𝑒 ( 𝑢 ) = ∑ ( 𝑥 , 𝑢 ) ∈ 𝐸 𝑓 ( 𝑥 , 𝑢 ) − ∑ ( 𝑢 , 𝑦 ) ∈ 𝐸 𝑓 ( 𝑢 , 𝑦 ) e ( u ) = ∑ ( x , u ) ∈ E f ( x , u ) − ∑ ( u , y ) ∈ E f ( u , y ) 上述将 ( 𝑠 , 𝑣 ) ∈ 𝐸 ( s , v ) ∈ E ℎ ( 𝑠 ) h ( s ) ( 𝑠 , 𝑣 ) ∉ 𝐸 𝑓 ( s , v ) ∉ E f ℎ ( 𝑠 ) > ℎ ( 𝑣 ) h ( s ) > h ( v ) ( 𝑠 , 𝑣 ) ( s , v ) 𝑒 ( 𝑠 ) e ( s ) ∑ ( 𝑠 , 𝑣 ) ∈ 𝐸 𝑓 ( 𝑠 , 𝑣 ) ∑ ( s , v ) ∈ E f ( s , v )
过程 我们每次扫描整个图,只要存在结点 𝑢 u
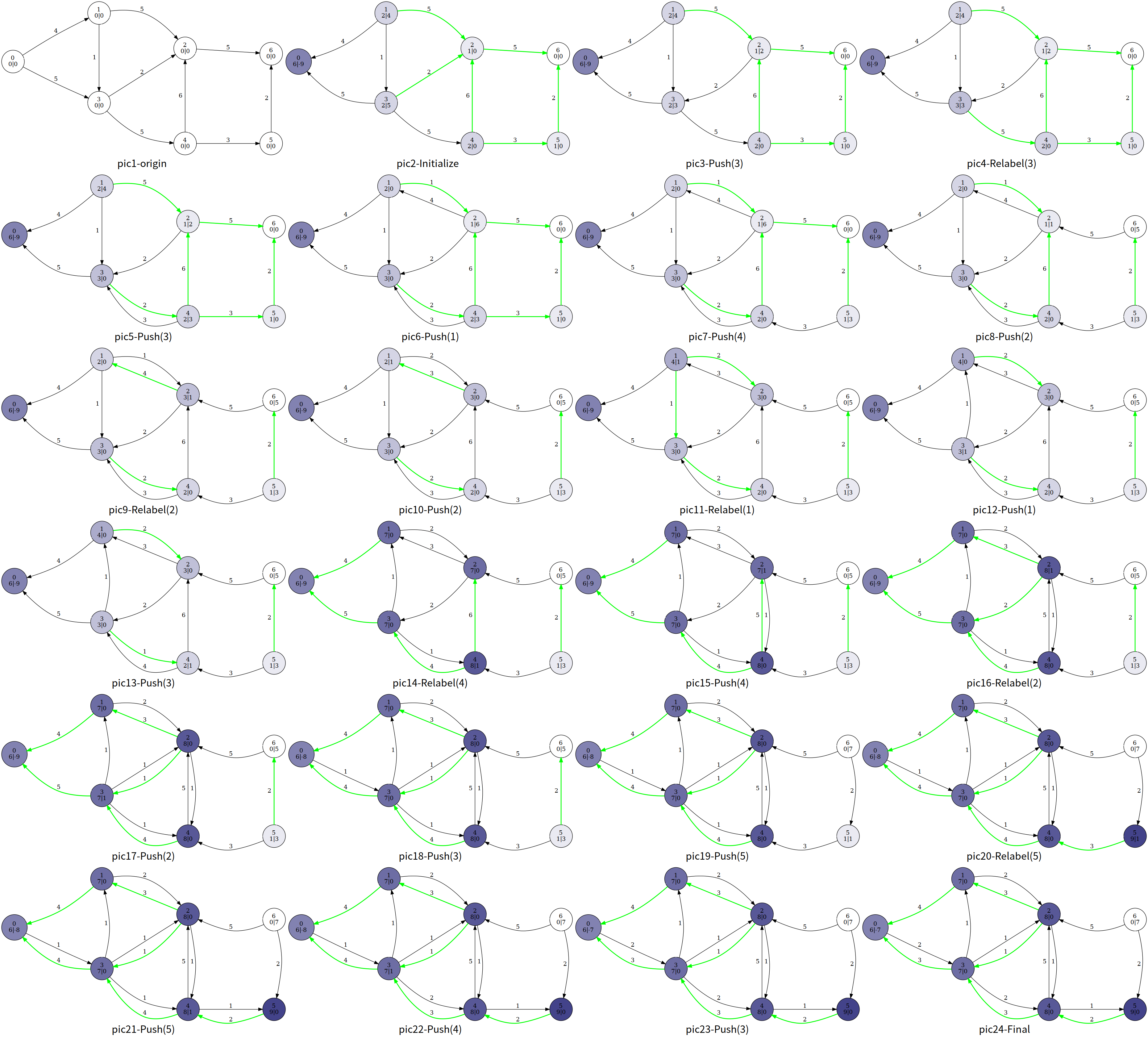
如图,每个结点中间表示编号,左下表示高度值 ℎ ( 𝑢 ) h ( u ) 𝑒 ( 𝑢 ) e ( u ) 𝑐 ( 𝑢 , 𝑣 ) − 𝑓 ( 𝑢 , 𝑣 ) c ( u , v ) − f ( u , v ) ℎ ( 𝑢 ) = ℎ ( 𝑣 ) + 1 h ( u ) = h ( v ) + 1 ( 𝑢 , 𝑣 ) ( u , v ) 𝐸 𝑓 E f
整个算法我们大致浏览一下过程,这里笔者使用的是一个暴力算法,即暴力扫描是否有溢出的结点,有就更新
最后的结果
可以发现,最后的超额流一部分回到了 𝑠 s 𝑓 f 𝑒 ( 𝑡 ) e ( t )
但是实际上论文𝑛 n
实现 核心代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 constexpr int N = 1e4 + 4 , M = 1e5 + 5 , INF = 0x3f3f3f3f ;
int n , m , s , t , maxflow , tot ;
int ht [ N ], ex [ N ];
void init () { // 初始化
for ( int i = h [ s ]; i ; i = e [ i ]. nex ) {
const int & v = e [ i ]. t ;
ex [ v ] = e [ i ]. v , ex [ s ] -= ex [ v ], e [ i ^ 1 ]. v = e [ i ]. v , e [ i ]. v = 0 ;
}
ht [ s ] = n ;
}
bool push ( int ed ) {
const int & u = e [ ed ^ 1 ]. t , & v = e [ ed ]. t ;
int flow = min ( ex [ u ], e [ ed ]. v );
ex [ u ] -= flow , ex [ v ] += flow , e [ ed ]. v -= flow , e [ ed ^ 1 ]. v += flow ;
return ex [ u ]; // 如果 u 仍溢出,返回 1
}
void relabel ( int u ) {
ht [ u ] = INF ;
for ( int i = h [ u ]; i ; i = e [ i ]. nex )
if ( e [ i ]. v ) ht [ u ] = min ( ht [ u ], ht [ e [ i ]. t ]);
++ ht [ u ];
}
HLPP 算法 最高标号预流推进算法(Highest Label Preflow Push)在上述通用的预流推送算法中,在每次选择结点时,都优先选择高度最高的溢出结点,其算法复杂度为 𝑂 ( 𝑛 2 √ 𝑚 ) O ( n 2 m )
过程 具体地说,HLPP 算法过程如下:
初始化(基于预流推进算法); 选择溢出结点中高度最高的结点 𝑢 u 如果 𝑢 u 如果没有溢出的结点,算法结束. 一篇对最大流算法实际表现进行测试的论文
BFS 优化 HLPP 的上界为 𝑂 ( 𝑛 2 √ 𝑚 ) O ( n 2 m ) ℎ ( 𝑢 ) h ( u ) 𝑢 u 𝑡 t ℎ ( 𝑠 ) = 𝑛 h ( s ) = n
在 BFS 的同时我们顺便检查图的连通性,排除无解的情况.
GAP 优化 HLPP 推送的条件是 ℎ ( 𝑢 ) = ℎ ( 𝑣 ) + 1 h ( u ) = h ( v ) + 1 𝑘 k ℎ ( 𝑢 ) = 𝑘 h ( u ) = k 0 0 ℎ ( 𝑢 ) > 𝑘 h ( u ) > k 𝑡 t 𝑠 s 𝑛 + 1 n + 1 𝑠 s
以下的实现采取论文𝑁 ∗ 2 − 1 N ∗ 2 − 1 B,其中 B[i] 中记录所有当前高度为 𝑖 i 𝑛 n
值得注意的是论文stack 默认的容器是 deque.经过简单的测试发现 vector,deque,list 在本题的实际运行过程中效率区别不大.
实现 LuoguP4722【模板】最大流 加强版/预流推进 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109 #include <cstdio>
#include <cstring>
#include <queue>
#include <stack>
using namespace std ;
constexpr int N = 1200 , M = 120000 , INF = 0x3f3f3f3f ;
int n , m , s , t ;
struct qxx {
int nex , t ;
long long v ;
};
qxx e [ M * 2 + 1 ];
int h [ N + 1 ], cnt = 1 ;
void add_path ( int f , int t , long long v ) {
e [ ++ cnt ] = qxx { h [ f ], t , v }, h [ f ] = cnt ;
}
void add_flow ( int f , int t , long long v ) {
add_path ( f , t , v );
add_path ( t , f , 0 );
}
int ht [ N + 1 ]; // 高度;
long long ex [ N + 1 ]; // 超额流;
int gap [ N ]; // gap 优化. gap[i] 为高度为 i 的节点的数量
stack < int > B [ N ]; // 桶 B[i] 中记录所有 ht[v]==i 的v
int level = 0 ; // 溢出节点的最高高度
int push ( int u ) { // 尽可能通过能够推送的边推送超额流
bool init = u == s ; // 是否在初始化
for ( int i = h [ u ]; i ; i = e [ i ]. nex ) {
const int & v = e [ i ]. t ;
const long long & w = e [ i ]. v ;
// 初始化时不考虑高度差为1
if ( ! w || ( init == false && ht [ u ] != ht [ v ] + 1 ) || ht [ v ] == INF ) continue ;
long long k = init ? w : min ( w , ex [ u ]);
// 取到剩余容量和超额流的最小值,初始化时可以使源的溢出量为负数.
if ( v != s && v != t && ! ex [ v ]) B [ ht [ v ]]. push ( v ), level = max ( level , ht [ v ]);
ex [ u ] -= k , ex [ v ] += k , e [ i ]. v -= k , e [ i ^ 1 ]. v += k ; // push
if ( ! ex [ u ]) return 0 ; // 如果已经推送完就返回
}
return 1 ;
}
void relabel ( int u ) { // 重贴标签(高度)
ht [ u ] = INF ;
for ( int i = h [ u ]; i ; i = e [ i ]. nex )
if ( e [ i ]. v ) ht [ u ] = min ( ht [ u ], ht [ e [ i ]. t ]);
if ( ++ ht [ u ] < n ) { // 只处理高度小于 n 的节点
B [ ht [ u ]]. push ( u );
level = max ( level , ht [ u ]);
++ gap [ ht [ u ]]; // 新的高度,更新 gap
}
}
bool bfs_init () {
memset ( ht , 0x3f , sizeof ( ht ));
queue < int > q ;
q . push ( t ), ht [ t ] = 0 ;
while ( q . size ()) { // 反向 BFS, 遇到没有访问过的结点就入队
int u = q . front ();
q . pop ();
for ( int i = h [ u ]; i ; i = e [ i ]. nex ) {
const int & v = e [ i ]. t ;
if ( e [ i ^ 1 ]. v && ht [ v ] > ht [ u ] + 1 ) ht [ v ] = ht [ u ] + 1 , q . push ( v );
}
}
return ht [ s ] != INF ; // 如果图不连通,返回 0
}
// 选出当前高度最大的节点之一, 如果已经没有溢出节点返回 0
int select () {
while ( level > -1 && B [ level ]. size () == 0 ) level -- ;
return level == -1 ? 0 : B [ level ]. top ();
}
long long hlpp () { // 返回最大流
if ( ! bfs_init ()) return 0 ; // 图不连通
memset ( gap , 0 , sizeof ( gap ));
for ( int i = 1 ; i <= n ; i ++ )
if ( ht [ i ] != INF ) gap [ ht [ i ]] ++ ; // 初始化 gap
ht [ s ] = n ;
push ( s ); // 初始化预流
int u ;
while (( u = select ())) {
B [ level ]. pop ();
if ( push ( u )) { // 仍然溢出
if ( !-- gap [ ht [ u ]])
for ( int i = 1 ; i <= n ; i ++ )
if ( i != s && ht [ i ] > ht [ u ] && ht [ i ] < n + 1 )
ht [ i ] = n + 1 ; // 这里重贴成 n+1 的节点都不是溢出节点
relabel ( u );
}
}
return ex [ t ];
}
int main () {
scanf ( "%d%d%d%d" , & n , & m , & s , & t );
for ( int i = 1 , u , v , w ; i <= m ; i ++ ) {
scanf ( "%d%d%d" , & u , & v , & w );
add_flow ( u , v , w );
}
printf ( "%lld" , hlpp ());
return 0 ;
}
感受一下运行过程
其中 pic13 到 pic14 执行了 Relabel(4),并进行了 GAP 优化.
脚注 2026/1/7 08:56:54 ,更新历史 在 GitHub 上编辑此页! sshwy , Tiphereth-A , StudyingFather , Ir1d , Marcythm , black-desk , Enter-tainer , MegaOwIer , Xeonacid , argvchs , c-forrest , HeRaNO , ksyx , Nanarikom , aofall , CCXXXI , Chrogeek , CoelacanthusHex , frank-xjh , gavinliu266 , iamtwz , ImpleLee , isdanni , Kaiser-Yang , Konano , LeeLin2602 , liqwang , megakite , ouuan , Persdre , PeterlitsZo , renbaoshuo , shuzhouliu , silvecor , Sshwy , Unnamed2964 , UserUnauthorized , Wajov , wen999di , wlbksy , zymooll CC BY-SA 4.0 和 SATA ")