复杂度简介 时间复杂度和空间复杂度是衡量一个算法效率的重要标准.
基本操作数 同一个算法在不同的计算机上运行的速度会有一定的差别,并且实际运行速度难以在理论上进行计算,实际去测量又比较麻烦,所以我们通常考虑的不是算法运行的实际用时,而是算法运行所需要进行的基本操作的数量.
在普通的计算机上,加减乘除、访问变量(基本数据类型的变量,下同)、给变量赋值等都可以看作基本操作.
对基本操作的计数或是估测可以作为评判算法用时的指标.
时间复杂度 定义 衡量一个算法的快慢,一定要考虑数据规模的大小.所谓数据规模,一般指输入的数字个数、输入中给出的图的点数与边数等等.一般来说,数据规模越大,算法的用时就越长.而在算法竞赛中,我们衡量一个算法的效率时,最重要的不是看它在某个数据规模下的用时,而是看它的用时随数据规模而增长的趋势,即 时间复杂度 .
引入 考虑用时随数据规模变化的趋势的主要原因有以下几点:
现代计算机每秒可以处理数亿乃至更多次基本运算,因此我们处理的数据规模通常很大.如果算法 A 在规模为 𝑛 n 1 0 0 𝑛 100 n 𝑛 n 𝑛 2 n 2 1 0 0 100 我们采用基本操作数来表示算法的用时,而不同的基本操作实际用时是不同的,例如加减法的用时远小于除法的用时.计算时间复杂度而忽略不同基本操作之间的区别以及一次基本操作与十次基本操作之间的区别,可以消除基本操作间用时不同的影响. 当然,算法的运行用时并非完全由输入规模决定,而是也与输入的内容相关.所以,时间复杂度又分为几种,例如:
最坏时间复杂度,即每个输入规模下用时最长的输入对应的时间复杂度.在算法竞赛中,由于输入可以在给定的数据范围内任意给定,我们为保证算法能够通过某个数据范围内的任何数据,一般考虑最坏时间复杂度. 平均(期望)时间复杂度,即每个输入规模下所有可能输入对应用时的平均值的复杂度(随机输入下期望用时的复杂度). 所谓「用时随数据规模而增长的趋势」是一个模糊的概念,我们需要借助下文所介绍的 渐近符号 来形式化地表示时间复杂度.
渐近符号的定义 渐近符号是函数的阶的规范描述.简单来说,渐近符号忽略了一个函数中增长较慢的部分以及各项的系数(在时间复杂度相关分析中,系数一般被称作「常数」),而保留了可以用来表明该函数增长趋势的重要部分.
一个简单的记忆方法是,含等于(非严格)用大写,不含等于(严格)用小写,相等是 Θ Θ 𝑂 O Ω Ω 𝑂 O 𝑜 o 𝑂 O 𝑜 o
在英文中,词根「-micro-」和「-mega-」常用于表示 10 的负六次方(百万分之一)和六次方(百万),也表示「小」和「大」.小和大也是希腊字母 Omicron 和 Omega 常表示的含义.
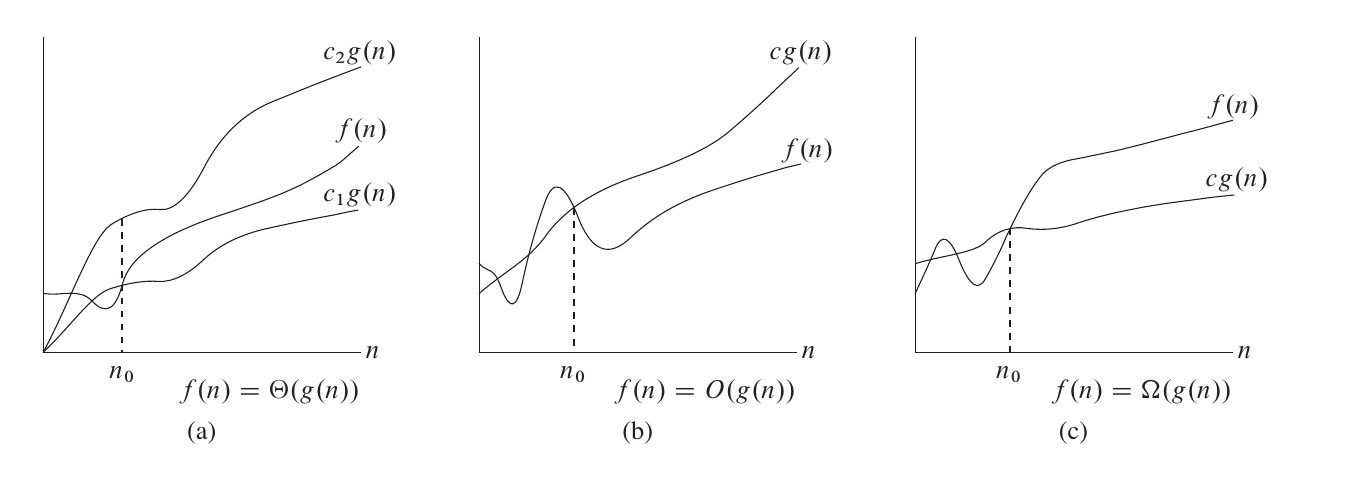
大 Θ 符号 对于函数 𝑓 ( 𝑛 ) f ( n ) 𝑔 ( 𝑛 ) g ( n ) 𝑓 ( 𝑛 ) = Θ ( 𝑔 ( 𝑛 ) ) f ( n ) = Θ ( g ( n ) ) ∃ 𝑐 1 , 𝑐 2 , 𝑛 0 > 0 ∃ c 1 , c 2 , n 0 > 0 ∀ 𝑛 ≥ 𝑛 0 , 0 ≤ 𝑐 1 ⋅ 𝑔 ( 𝑛 ) ≤ 𝑓 ( 𝑛 ) ≤ 𝑐 2 ⋅ 𝑔 ( 𝑛 ) ∀ n ≥ n 0 , 0 ≤ c 1 ⋅ g ( n ) ≤ f ( n ) ≤ c 2 ⋅ g ( n )
也就是说,如果函数 𝑓 ( 𝑛 ) = Θ ( 𝑔 ( 𝑛 ) ) f ( n ) = Θ ( g ( n ) ) 𝑐 1 , 𝑐 2 c 1 , c 2 𝑓 ( 𝑛 ) f ( n ) 𝑐 1 ⋅ 𝑔 ( 𝑛 ) c 1 ⋅ g ( n ) 𝑐 2 ⋅ 𝑔 ( 𝑛 ) c 2 ⋅ g ( n )
例如,3 𝑛 2 + 5 𝑛 − 3 = Θ ( 𝑛 2 ) 3 n 2 + 5 n − 3 = Θ ( n 2 ) 𝑐 1 , 𝑐 2 , 𝑛 0 c 1 , c 2 , n 0 2 , 4 , 1 0 0 2 , 4 , 100 𝑛 √ 𝑛 + 𝑛 l o g 5 𝑛 + 𝑚 l o g 𝑚 + 𝑛 𝑚 = Θ ( 𝑛 √ 𝑛 + 𝑚 l o g 𝑚 + 𝑛 𝑚 ) n n + n log 5 n + m log m + n m = Θ ( n n + m log m + n m ) 𝑐 1 , 𝑐 2 , 𝑛 0 c 1 , c 2 , n 0 1 , 2 , 1 0 0 1 , 2 , 100
大 O 符号 Θ Θ 𝑂 O 𝑓 ( 𝑛 ) = 𝑂 ( 𝑔 ( 𝑛 ) ) f ( n ) = O ( g ( n ) ) ∃ 𝑐 , 𝑛 0 ∃ c , n 0 ∀ 𝑛 ≥ 𝑛 0 , 0 ≤ 𝑓 ( 𝑛 ) ≤ 𝑐 ⋅ 𝑔 ( 𝑛 ) ∀ n ≥ n 0 , 0 ≤ f ( n ) ≤ c ⋅ g ( n )
研究时间复杂度时通常会使用 𝑂 O
需要注意的是,这里的「上界」和「下界」是对于函数的变化趋势而言的,而不是对算法而言的.算法用时的上界对应的是「最坏时间复杂度」而非大 𝑂 O Θ Θ Θ Θ 𝑂 O 𝑂 O 𝑂 O
大 Ω 符号 同样的,我们使用 Ω Ω 𝑓 ( 𝑛 ) = Ω ( 𝑔 ( 𝑛 ) ) f ( n ) = Ω ( g ( n ) ) ∃ 𝑐 , 𝑛 0 ∃ c , n 0 ∀ 𝑛 ≥ 𝑛 0 , 0 ≤ 𝑐 ⋅ 𝑔 ( 𝑛 ) ≤ 𝑓 ( 𝑛 ) ∀ n ≥ n 0 , 0 ≤ c ⋅ g ( n ) ≤ f ( n )
小 o 符号 如果说 𝑂 O 𝑜 o
小 𝑜 o 𝑜 o
𝑓 ( 𝑛 ) = 𝑜 ( 𝑔 ( 𝑛 ) ) f ( n ) = o ( g ( n ) ) 𝑐 c ∃ 𝑛 0 ∃ n 0 ∀ 𝑛 ≥ 𝑛 0 , 0 ≤ 𝑓 ( 𝑛 ) < 𝑐 ⋅ 𝑔 ( 𝑛 ) ∀ n ≥ n 0 , 0 ≤ f ( n ) < c ⋅ g ( n )
小 ω 符号 如果说 Ω Ω 𝜔 ω
𝑓 ( 𝑛 ) = 𝜔 ( 𝑔 ( 𝑛 ) ) f ( n ) = ω ( g ( n ) ) 𝑐 c ∃ 𝑛 0 ∃ n 0 ∀ 𝑛 ≥ 𝑛 0 , 0 ≤ 𝑐 ⋅ 𝑔 ( 𝑛 ) < 𝑓 ( 𝑛 ) ∀ n ≥ n 0 , 0 ≤ c ⋅ g ( n ) < f ( n )
常见性质 𝑓 ( 𝑛 ) = Θ ( 𝑔 ( 𝑛 ) ) ⟺ 𝑓 ( 𝑛 ) = 𝑂 ( 𝑔 ( 𝑛 ) ) ∧ 𝑓 ( 𝑛 ) = Ω ( 𝑔 ( 𝑛 ) ) f ( n ) = Θ ( g ( n ) ) ⟺ f ( n ) = O ( g ( n ) ) ∧ f ( n ) = Ω ( g ( n ) ) 𝑓 1 ( 𝑛 ) + 𝑓 2 ( 𝑛 ) = 𝑂 ( m a x ( 𝑓 1 ( 𝑛 ) , 𝑓 2 ( 𝑛 ) ) ) f 1 ( n ) + f 2 ( n ) = O ( max ( f 1 ( n ) , f 2 ( n ) ) ) 𝑓 1 ( 𝑛 ) × 𝑓 2 ( 𝑛 ) = 𝑂 ( 𝑓 1 ( 𝑛 ) × 𝑓 2 ( 𝑛 ) ) f 1 ( n ) × f 2 ( n ) = O ( f 1 ( n ) × f 2 ( n ) ) ∀ 𝑎 ≠ 1 , l o g 𝑎 𝑛 = 𝑂 ( l o g 2 𝑛 ) ∀ a ≠ 1 , log a n = O ( log 2 n ) 简单的时间复杂度计算的例子 for 循环如果以输入的数值 𝑛 n 𝑚 m Θ ( 𝑛 2 𝑚 ) Θ ( n 2 m )
DFS 在对一张 𝑛 n 𝑚 m DFS 时,由于每个节点和每条边都只会被访问常数次,复杂度为 Θ ( 𝑛 + 𝑚 ) Θ ( n + m )
哪些量是常量? 当我们要进行若干次操作时,如何判断这若干次操作是否影响时间复杂度呢?例如:
如果 𝑁 N 𝑂 ( 1 ) O ( 1 )
进行时间复杂度计算时,哪些变量被视作输入规模是很重要的,而所有和输入规模无关的量都被视作常量,计算复杂度时可当作 1 1
需要注意的是,在进行时间复杂度相关的理论性讨论时,「算法能够解决任何规模的问题」是一个基本假设(当然,在实际中,由于时间和存储空间有限,无法解决规模过大的问题).因此,能在常量时间内解决数据规模有限的问题(例如,对于数据范围内的每个可能输入预先计算出答案)并不能使一个算法的时间复杂度变为 𝑂 ( 1 ) O ( 1 )
主定理 (Master Theorem) 我们可以使用 Master Theorem 来快速求得关于递归算法的复杂度. Master Theorem 递推关系式如下
𝑇 ( 𝑛 ) = 𝑎 𝑇 ( 𝑛 𝑏 ) + 𝑓 ( 𝑛 ) ∀ 𝑛 > 𝑏 T ( n ) = a T ( n b ) + f ( n ) ∀ n > b 那么
𝑇 ( 𝑛 ) = ⎧ { { ⎨ { { ⎩ Θ ( 𝑛 l o g 𝑏 𝑎 ) 𝑓 ( 𝑛 ) = 𝑂 ( 𝑛 l o g 𝑏 ( 𝑎 ) − 𝜖 ) , 𝜖 > 0 Θ ( 𝑓 ( 𝑛 ) ) 𝑓 ( 𝑛 ) = Ω ( 𝑛 l o g 𝑏 ( 𝑎 ) + 𝜖 ) , 𝜖 ≥ 0 Θ ( 𝑛 l o g 𝑏 𝑎 l o g 𝑘 + 1 𝑛 ) 𝑓 ( 𝑛 ) = Θ ( 𝑛 l o g 𝑏 𝑎 l o g 𝑘 𝑛 ) , 𝑘 ≥ 0 T ( n ) = { Θ ( n log b a ) f ( n ) = O ( n log b ( a ) − ϵ ) , ϵ > 0 Θ ( f ( n ) ) f ( n ) = Ω ( n log b ( a ) + ϵ ) , ϵ ≥ 0 Θ ( n log b a log k + 1 n ) f ( n ) = Θ ( n log b a log k n ) , k ≥ 0 需要注意的是,这里的第二种情况还需要满足 regularity condition, 即 𝑎 𝑓 ( 𝑛 / 𝑏 ) ≤ 𝑐 𝑓 ( 𝑛 ) a f ( n / b ) ≤ c f ( n ) 𝑐 < 1 c < 1 𝑛 n
证明思路是将规模为 𝑛 n 𝑎 a ( 𝑛 𝑏 ) ( n b ) 𝑓 ( 𝑛 ) f ( n )
证明 依据上文提到的证明思路,具体证明过程如下
对于第 0 0 𝑓 ( 𝑛 ) f ( n )
对于第 1 1 𝑎 a 𝑓 ( 𝑛 𝑏 ) f ( n b ) 𝑎 𝑓 ( 𝑛 𝑏 ) a f ( n b )
层层递推,我们可以写出类推树如下:
这棵树的高度为 l o g 𝑏 𝑛 log b n 𝑛 l o g 𝑏 𝑎 n log b a 𝑇 ( 𝑛 ) = Θ ( 𝑛 l o g 𝑏 𝑎 ) + 𝑔 ( 𝑛 ) T ( n ) = Θ ( n log b a ) + g ( n ) 𝑔 ( 𝑛 ) = ∑ l o g 𝑏 𝑛 − 1 𝑗 = 0 𝑎 𝑗 𝑓 ( 𝑛 / 𝑏 𝑗 ) g ( n ) = ∑ j = 0 log b n − 1 a j f ( n / b j )
针对于第一种情况:𝑓 ( 𝑛 ) = 𝑂 ( 𝑛 l o g 𝑏 𝑎 − 𝜖 ) f ( n ) = O ( n log b a − ϵ ) 𝑔 ( 𝑛 ) = 𝑂 ( 𝑛 l o g 𝑏 𝑎 ) g ( n ) = O ( n log b a )
对于第二种情况而言:首先 𝑔 ( 𝑛 ) = Ω ( 𝑓 ( 𝑛 ) ) g ( n ) = Ω ( f ( n ) ) 𝑎 𝑓 ( 𝑛 𝑏 ) ≤ 𝑐 𝑓 ( 𝑛 ) a f ( n b ) ≤ c f ( n ) 𝑐 c 𝑛 n 𝑔 ( 𝑛 ) = 𝑂 ( 𝑓 ( 𝑛 ) g ( n ) = O ( f ( n ) 𝑔 ( 𝑛 ) = Θ ( 𝑓 ( 𝑛 ) ) g ( n ) = Θ ( f ( n ) )
而对于第三种情况:𝑓 ( 𝑛 ) = Θ ( 𝑛 l o g 𝑏 𝑎 ) f ( n ) = Θ ( n log b a ) 𝑔 ( 𝑛 ) = 𝑂 ( 𝑛 l o g 𝑏 𝑎 l o g 𝑛 ) g ( n ) = O ( n log b a log n ) 𝑇 ( 𝑛 ) T ( n ) 𝑔 ( 𝑛 ) g ( n )
下面举几个例子来说明主定理如何使用.
𝑇 ( 𝑛 ) = 2 𝑇 ( 𝑛 2 ) + 1 T ( n ) = 2 T ( n 2 ) + 1 𝑎 = 2 , 𝑏 = 2 , l o g 2 2 = 1 a = 2 , b = 2 , log 2 2 = 1 𝜖 ϵ ( 0 , 1 ] ( 0 , 1 ] 𝑇 ( 𝑛 ) = Θ ( 𝑛 ) T ( n ) = Θ ( n )
𝑇 ( 𝑛 ) = 𝑇 ( 𝑛 2 ) + 𝑛 T ( n ) = T ( n 2 ) + n 𝑎 = 1 , 𝑏 = 2 , l o g 2 1 = 0 a = 1 , b = 2 , log 2 1 = 0 𝜖 ϵ ( 0 , 1 ] ( 0 , 1 ] 𝑇 ( 𝑛 ) = Θ ( 𝑛 ) T ( n ) = Θ ( n )
𝑇 ( 𝑛 ) = 𝑇 ( 𝑛 2 ) + l o g 𝑛 T ( n ) = T ( n 2 ) + log n 𝑎 = 1 , 𝑏 = 2 , l o g 2 1 = 0 a = 1 , b = 2 , log 2 1 = 0 𝑘 k 1 1 𝑇 ( 𝑛 ) = Θ ( l o g 2 𝑛 ) T ( n ) = Θ ( log 2 n )
𝑇 ( 𝑛 ) = 𝑇 ( 𝑛 2 ) + 1 T ( n ) = T ( n 2 ) + 1 𝑎 = 1 , 𝑏 = 2 , l o g 2 1 = 0 a = 1 , b = 2 , log 2 1 = 0 𝑘 k 0 0 𝑇 ( 𝑛 ) = Θ ( l o g 𝑛 ) T ( n ) = Θ ( log n )
均摊复杂度 详情可见 均摊复杂度 .
空间复杂度 类似地,算法所使用的空间随输入规模变化的趋势可以用 空间复杂度 来衡量.
计算复杂性 本文主要从算法分析的角度对复杂度进行了介绍,如果有兴趣的话可以在 计算复杂性 进行更深入的了解.
2026/5/13 11:36:39 ,更新历史 在 GitHub 上编辑此页! Ir1d , ouuan , Tiphereth-A , Enter-tainer , GuanghaoYe , Persdre , CCXXXI , Great-designer , iamtwz , ksyx , linehk , shuzhouliu , sshwy , abc1763613206 , aquastripe , Backl1ght , blackwhitetony , c-forrest , chinggg , Enonya , GreyTigerOIer , he-zhiyuan , isdanni , Konano , lailai0916 , Marcythm , Menci , mgt , nullnan , onelittlechildawa , partychicken , persdre , shawlleyw , TianyiQ , wr786 , Xeonacid , YHN-ice , yyyu-star , zirnc CC BY-SA 4.0 和 SATA